
爬虫学习(二) ---Scrapy
爬虫框架学习(二) ---Scrapy
上期好像说更Docker来着( ̄o ̄)
忘了忘了,先说爬虫吧 ๑乛◡乛๑
原本想继续更feapder来着,但是网上找的很多动态页面爬取教程都是基于Scrapy的,所以换Scrapy学一下
学会了再转回feapder
安装及初始化
#安装
pip install Scrapy
#创建项目
scrapy startproject project_name
#初始化
cd ./project_name
scrapy genspider example example.com
目录介绍
project_folder -- 项目文件夹名称 | |──project_name -- 该项目的python模块,一般和项目文件夹名称相同 | | | |──spider -- 放置spider代码的包,以后所有的爬虫,都存放在这个里面 | | | |──items.py -- 用来存放爬虫怕写来的数据的模型 | | | |──middlewares.py -- 用来存放各种中间件的文件 | | | |──pipelines.py -- 用来对items里面提取的数据做进一步处理,如保存到本地磁盘等 | | | |──settings.py -- 本爬虫的一些配置信息(如请求头、多久发送一次请求、ip代理池等) | |──scrapy.cfg -- 项目的配置文件
感觉和feapder差不多,但更规范和完整,feapder提供的更多是封装和便捷
有余力的可以看一下feapder的Spider文档
基础命令
#运行
scrapy crawl spider_name
#列出所有Spider
scrapy list
#运行Spider并将结果保存
#Json
scrapy crawl spider_name -o output.json
#CSV
scrapy crawl spider_name -o output.csv
#XML
scrapy crawl spider_name -o output.xml
#标准输出
scrapy crawl spider_name -t json
示例
这次的受害人依旧是X博
╰(*′ ︶ ` *)╯
步骤
- 初始化scrapy项目
- 分析动态网站
静态网站与动态网站的区别:
向静态网站发送请求后,服务器会返回完整的网页源码(各类资源直接从数据库返回)
动态网站不一样,发送请求后,整体源码返回内容一致。
但就像我们日常使用一样,越往下拉,更新越多,不往下拉反而没有相应的内容更新,Vue会监听滚轮情况,然后选择是否增加新的组件
因此想要爬取相应的动态内容,最好亲自抓包
例如我下拉页面时控制台监听到新的请求
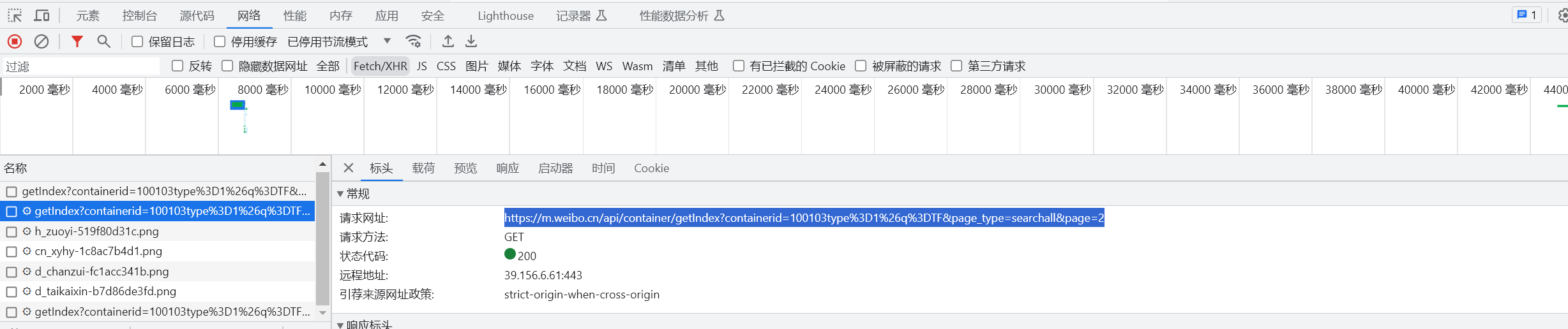
请注意,这里的URL其实是对应的API,而不是真正的URL,下文中的URL也可以看成是API
观察网址,其实大部分的参数都放在URL内部,后期也可以直接通过修改URL来对相应内容发出请求。
点开响应页面,可以直接看到,返回的就是网页新增的内容(JSON格式)
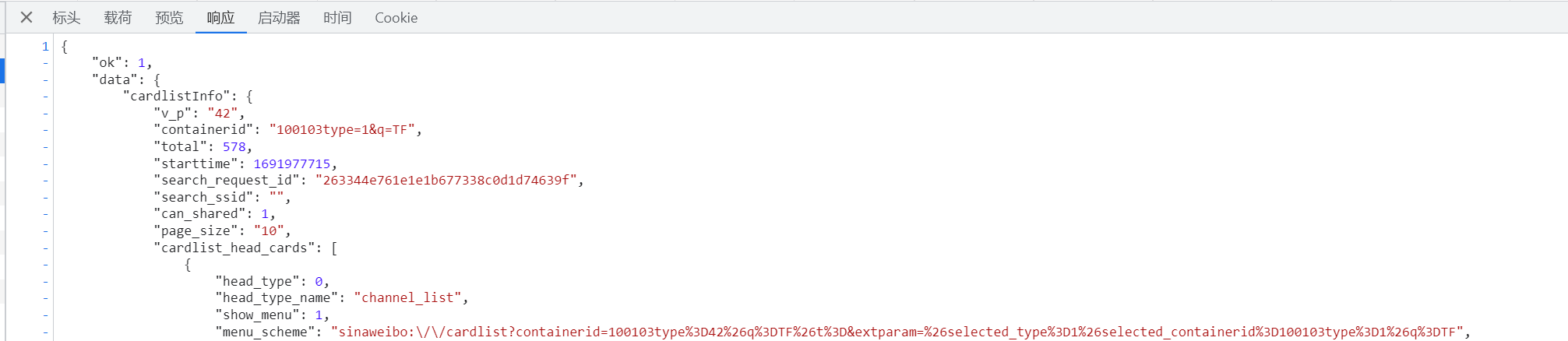
但是,可以看出返回的并不是直接的内容
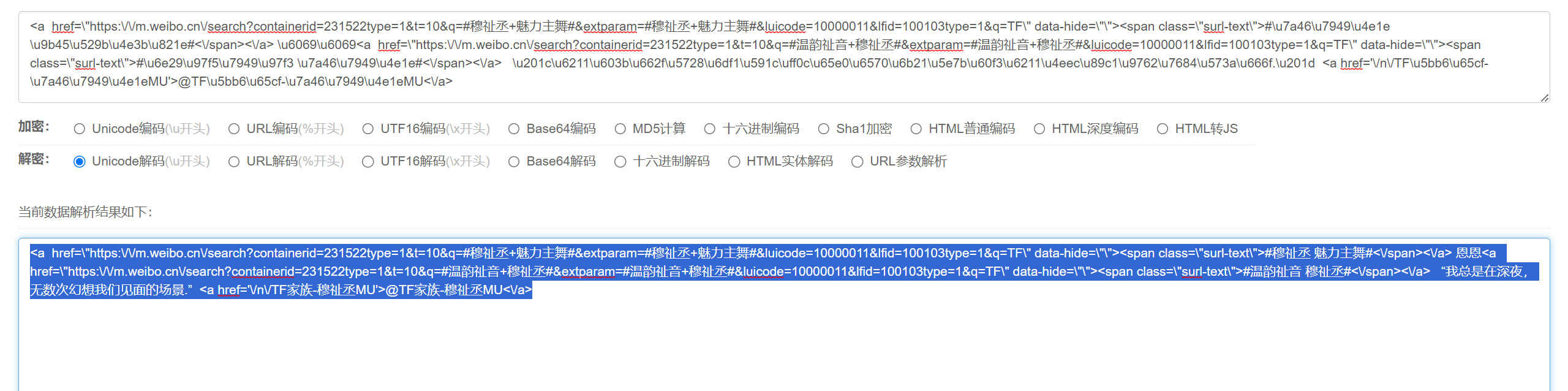
我们再具体取出其中一部分分析一下(已去链接)
<\a href="https://mweibocn/search?containerid=231522type%3D1%26t%3D10%26q%3D%23%E7%A9%86%E7%A5%89%E4%B8%9E+%E9%AD%85%E5%8A%9B%E4%B8%BB%E8%88%9E%23&extparam=%23%E7%A9%86%E7%A5%89%E4%B8%9E+%E9%AD%85%E5%8A%9B%E4%B8%BB%E8%88%9E%23&luicode=10000011&lfid=100103type%3D1%26q%3DTF" data-hide=""><span class="surl-text">#\u7a46\u7949\u4e1e \u9b45\u529b\u4e3b\u821e#</span></a> \u201c\u6211\u603b\u662f\u5728\u6df1\u591c\uff0c\u65e0\u6570\u6b21\u5e7b\u60f3\u6211\u4eec\u89c1\u9762\u7684\u573a\u666f.\u201d <\a href='/n/TF\u5bb6\u65cf-\u7a46\u7949\u4e1eMU'>@TF\u5bb6\u65cf-\u7a46\u7949\MU</a>
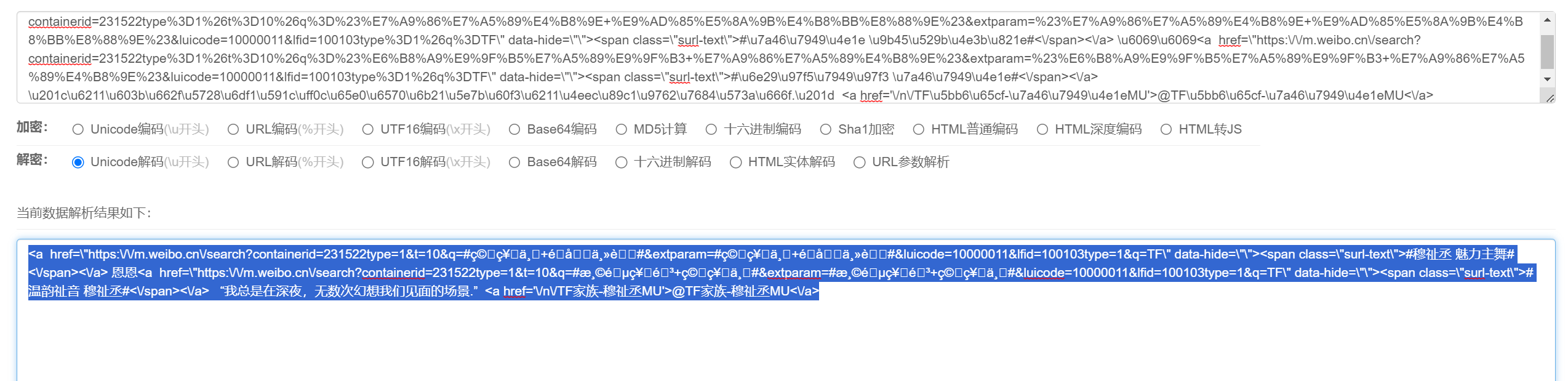
emmmmm,总的来说就是同时用了unicode和URL两种编码混合的方式,如下面两张图所示
- Unicode
- URL
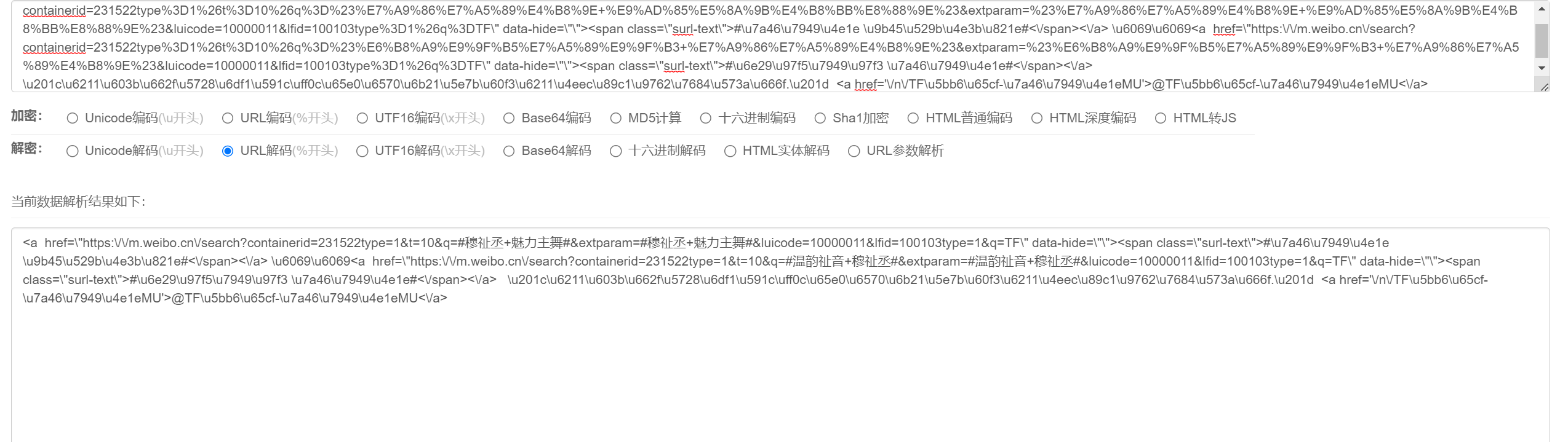
所以先进行URL解析,然后进行Unicode解析即可获取真实内容
(;¬_¬)
这样看来有点麻烦,有没有更好一点的解决办法,让我们能直接拿到JS渲染结束后的页面内容呢?
有!这就是我们下一章的主角-------selenium
先在这给一份简单介绍和示例,具体请关注下次更新
应用场景介绍:
- JavaScript渲染页面: 当目标网站使用大量JavaScript来渲染内容,而传统的爬虫无法正确解析页面时,你可以使用Selenium来模拟浏览器行为,使得页面中的动态内容能够被加载和解析。
- 模拟用户交互: 有些网站要求用户执行一些交互操作,比如点击按钮、填写表单、选择下拉菜单等才能获取到所需的数据。在这种情况下,你可以使用Selenium来模拟这些用户交互动作,然后获取数据。
- 需要登录的网站: 如果目标网站需要用户登录才能访问特定内容,你可以使用Selenium来模拟登录过程,以便在爬取过程中保持登录状态。
- 反爬虫手段: 有些网站可能会采取一些反爬虫手段,比如检测用户代理、验证JavaScript渲染等。使用Selenium可以模仿真实的浏览器行为,从而减少被识别为爬虫的可能性。
- 验证验证码: 如果目标网站在爬取过程中需要用户输入验证码才能继续访问,你可以使用Selenium来自动处理验证码输入过程。
- 爬虫示例
# import scrapy
# from selenium import webdriver
# from scrapy.http import HtmlResponse
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, callback=self.parse, dont_filter=True)
def parse(self, response):
# Use a context manager to automatically close the driver
with webdriver.Chrome() as driver: # You might need to adjust this depending on your setup
driver.get(response.url)
content = driver.page_source
# Now you can create an HtmlResponse with the rendered content
rendered_response = HtmlResponse(url=response.url, body=content, encoding='utf-8')
self.parse_rendered_page(rendered_response) # Call your parsing function
def parse_rendered_page(self, response):
# Use XPath to extract the desired text
elements = response.xpath('//*/text()').get()
for element in elements:
if element:
print("Element:", element.strip())
else:
print("NONE!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
pass
这里只提供了简化版本,即直接在解析函数中使用selenium的webdriver对相应的页面进行渲染。。。。
说白了就是直接用chrome打开对应的页面,然后利用Xpath进行匹配
其实也可以通过中间件的方式进行渲染,例子如下:
# middleware.py
class SeleniumMiddleware:
def __init__(self):
self.options = webdriver.ChromeOptions()
self.options.add_argument('--headless')
self.options.add_argument('--disable-gpu')
self.options.add_argument("no-sandbox")
self.options.add_argument("disable-blink-features=AutomationControlled")
self.options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.driver = webdriver.Chrome(options=self.options)
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
def process_request(self, request, spider):
self.driver.get(request.url)
self.driver.implicitly_wait(5)
content = self.driver.page_source
return HtmlResponse(request.url, encoding="utf-8", body=content, request=request)
def __del__(self):
self.driver.quit()
# settings.py
DOWNLOADER_MIDDLEWARES = {
...
'Spider.middlewares.SeleniumMiddleware': 543,
}
但是真的好慢。。。肉眼可见的慢,因为你要看着它打开页面,然后看着它关闭
| API+解析 | URL+selenium | |
|---|---|---|
| 速度 | 快 | 慢 |
| 复杂度 | 高 | 低 |
两个框架的区别
结尾部分给出一份GPT对feapder和Scrapy的特色对比
Scrapy:
- 成熟度和社区支持: Scrapy是一个非常成熟和广泛使用的爬虫框架,有着强大的社区支持和活跃的开发团队。它在爬虫领域有着广泛的应用和稳定的历史。
- 异步框架: Scrapy采用异步的架构,可以高效地管理并发请求,从而提高爬取效率。它使用Twisted异步网络库来处理IO操作,使得在单线程中可以处理多个并发请求。
- 丰富的中间件和扩展: Scrapy提供了许多中间件和扩展,可以灵活地处理请求、响应、爬取过程等不同方面的操作。这使得你可以自定义和控制爬虫的各个阶段。
- 自动化: Scrapy提供了自动处理链接和跟进链接的功能,以及针对不同网站的User-Agent和Cookie管理。这使得构建通用爬虫变得更容易。
- 大型项目支持: Scrapy适用于构建大型、复杂的爬虫项目,可以管理多个Spider并分配资源,同时提供日志、统计和错误处理等功能。
Feapder:
- 轻量级和简单: Feapder被设计为一个轻量级的爬虫框架,着重于简洁的API和易于上手的特点。它的代码库相对较小,因此适合快速开发小型爬虫项目。
- 协程异步: Feapder使用协程(coroutine)来实现异步操作,通过asyncio库来管理异步事件循环。这使得在单线程中处理并发请求变得更加高效。
- 支持分布式: Feapder天然支持分布式爬取,你可以在多台机器上运行爬虫实例,并通过调度器协调任务。这对于需要大规模数据采集的项目非常有用。
- 无依赖的可执行文件: Feapder可以将爬虫代码和依赖打包成一个独立的可执行文件,这样你可以在不同环境中运行爬虫而无需手动安装依赖。
- 小型项目和快速原型: Feapder适用于小型项目、快速原型开发,以及一些简单的爬取需求。它的简单性使得非开发背景的用户也能够快速上手。
总结
| Scrapy | feapder | |
|---|---|---|
| 规模 | 大型 | 轻量 |
| 异步 | 使用Twisted异步网络库来处理IO操作 | 使用协程(coroutine)来实现异步操作,通过asyncio库来管理异步事件循环 |
具体来讲,其实feapder应该会比Scrapy更快,但是可能欠规范,尤其是数据过滤和清洗这块
参考文档
 ---Scrapy&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/01/16/20240116-200238.jpg&summary=新的尝试,更深入的理解){kind=link}
 ---Scrapy&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/01/16/20240116-200238.jpg&desc=新的尝试,更深入的理解){kind=link}
 微信
微信
 支付宝
支付宝