
爬虫学习(三)---Selenium及总结
爬虫学习(三) ---Selenium及总结
漫长的爬取终于要告一段落了(可怜的打工人
这期填一下上期爬虫留的坑---Selenium
顺便给自己的爬取项目做个总结
Selenium
# 安装
pip install selenium
# 引入(selenium中的webdriver)
from selenium import webdriver
# 初始化
options = webdriver.ChromeOptions()
# 无头访问(即后台运行,不需要打开浏览器)
options.add_argument("--headless")
# 禁用GPU加速
# 原因:因为是无头访问,所以不需要看到对应的图形元素,所以不需要开启GPU加速。以此减少资源消耗,加快爬取速度
options.add_argument("--disable-gpu")
# 禁用沙盒安全模式 (Linux环境下比较适用)
# 原因:同样是为了降低性能损耗
options.add_argument("--no-sandbox")
# 启动浏览器
browser = webdriver.Chrome(options=options)
组件介绍:
- Selenium WebDriver:这是 Selenium 的核心组件,它提供了与不同浏览器(如Chrome,Firefox,Edge等)交互的API。WebDriver 允许你启动浏览器,导航到网页,执行操作(例如点击,输入文本等),并获取页面元素的信息。
- Selenium Grid:这是一个用于并行测试的工具,它允许你在多个浏览器和不同的计算机上同时运行测试。Selenium Grid 可以用于在不同配置的浏览器上并行运行测试,以加快测试速度。
- Selenium IDE:这是一个浏览器插件,用于记录和回放用户在浏览器中的操作,以生成测试脚本。它通常用于快速创建简单的测试用例。
- Selenium Client Libraries:Selenium 提供了各种编程语言的客户端库,包括Java,Python,C#,JavaScript等。这些库允许你在不同的编程语言中使用 Selenium 来编写测试脚本和自动化任务。
- Selenium WebDriver API:这是用于与浏览器交互的API,可以通过编程来控制浏览器的行为。它包括一系列方法和类,用于模拟用户在浏览器中的操作。
示例
根据项目需要,这次的受害人为:**百科
╰(′︶`)╯
以下示例是 Selenium 嵌入到 feapder 框架的解析函数中
然后实现 模拟访问
def parse(self, request, response):
# # 提取网站title
# print(response.xpath("//title/text()").extract_first())
# # 提取网站描述
# print(response.xpath("//meta[@name='description']/@content").extract_first())
url = response.url
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
browser = webdriver.Chrome(options=options)
browser.get(url)
current_url = browser.current_url
page_source = browser.page_source
browser.quit()
print("current url: " + current_url)
unicode_escapes = re.findall(r'\\u[0-9a-fA-F]{4}', page_source)
# decoded_page_source = page_source.encode("latin1").decode("utf-8")
decoded_page_source = page_source
for escape in unicode_escapes:
decoded = json.loads('["' + escape + '"]')[0]
decoded_page_source = decoded_page_source.replace(escape, decoded)
div_pattern = r'<div class="para MARK_MODULE"[^>]*>(.*?)</div>'
div_matches = re.findall(div_pattern, decoded_page_source, re.DOTALL)
# 解析 HTML 字符串为 BeautifulSoup 文档
soup = BeautifulSoup(decoded_page_source, 'html.parser')
# 选择特定的 <div> 元素
div_elements = soup.find_all("div", class_="para MARK_MODULE")
title_element = soup.find("h1")
if title_element:
title_text = title_element.get_text(strip=True) # 获取文本内容,strip=True 去除多余的空白字符
# print(title_text)
else:
title_text = "No title found."
# 提取每个 <div> 下的所有中文文本
chinese_texts = []
for div in div_elements:
chinese_text = ''.join([text for text in div.stripped_strings if any(c.isalpha() for c in text)])
if chinese_text and len(chinese_text) > 15:
cleaned_text = self.filter_empty_lines(chinese_text)
chinese_texts.append(cleaned_text)
...
Tips:
-
page_source 本身为 String 类型,因此不能像之前一样使用XPath去进行匹配,
-
示例如下(未进行HTML渲染和Unicode转义)
-
-
使用 re 库直接正则匹配不如使用 Soup ,Soup能匹配出更好的效果
-
示例如下(左:re;右:Soup):
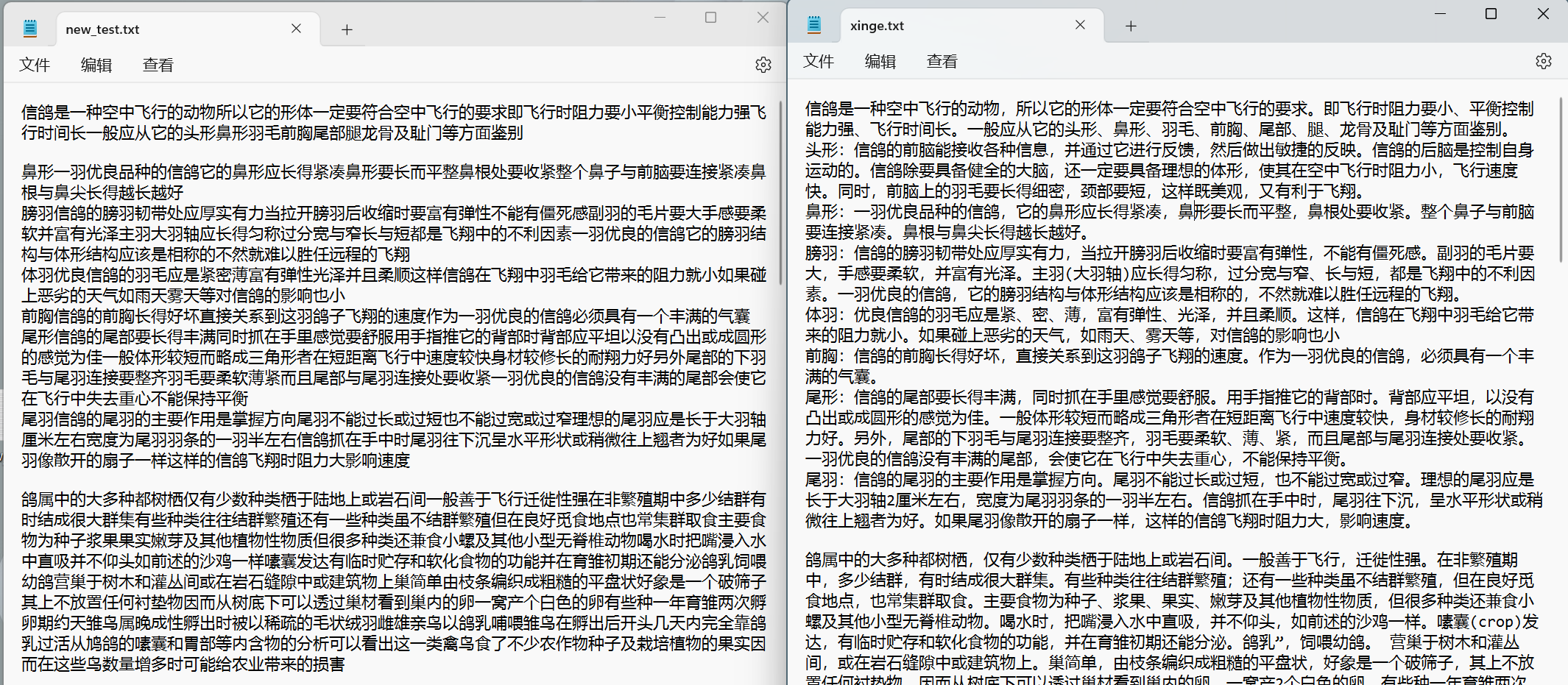
可以看出,Soup不仅能匹配中文,还可以直接匹配出中文的符号(:)
-
-
清洗去重和格式化比较简单,这里不过多赘述
-
提供一个简单示例
import json import io import os txt_files = [] for root, dirs, files in os.walk('人民日报'): for file in files: if file.endswith('.txt'): txt_files.append(os.path.join(root, file)) # Read the content from the text file # with open('renmin.txt', 'r', encoding='utf-8') as file: # content = file.read() # Initialize a list to store the parsed data from this file all_parsed_data = [] # ignore some error without utf-8 def clean_text(line): # Remove non-UTF-8 characters cleaned_line = line.decode('utf-8', 'ignore').encode('utf-8') return cleaned_line for txt_file in txt_files: # make new file folder json_dir = os.path.join(os.path.dirname(txt_file), 'Json') if not os.path.exists(json_dir): os.makedirs(json_dir) # decode the file with io.open(txt_file, 'r', encoding='utf-8',errors='replace') as file: content = file.read() # for line in lines: # cleaned_line = clean_text(line) # decoded_line = cleaned_line.decode('utf-8') # Split the content into individual articles articles = content.split('------------------------------------') parsed_data = [] # Iterate through each article and extract relevant information for article in articles: if article.strip(): # Check if the article is not empty lines = article.strip().split('\n') # Initialize a list to store the parsed data from this file title = lines[0][3:].strip() # print(title)# Extract title url = lines[1][3:] # Extract URL text = '\n'.join(lines[3:]) # Extract and join the remaining lines as text if len(text) >= 50 and len(title) > 3: # Create a dictionary for the article article_data = { "tittle": title, "url": url, "content": text } # Append the parsed data from this file to the overall list parsed_data.append(article_data) # Append the parsed data from this file to the overall list # Write the parsed data to a JSON file in the output folder json_file_name = f'{os.path.splitext(os.path.basename(txt_file))[0]}.json' json_file_path = os.path.join(json_dir, json_file_name) with open(json_file_path, 'w', encoding='utf-8') as json_file: json.dump(parsed_data, json_file, ensure_ascii=False, indent=2) print(f"{json_file_name} 已成功创建。")
-
步骤归纳
- 完善相关配置
- 启动访问
- 获取对应页面后进行解析(获取到的页面元素为String类型)
- 使用 re 库和 json.load() 方法将 Unicode 转义序列解码 然后进行替换
- 然后使用 BeautifulSoup 对HTML字符串进行解析
- 使用Soup进行匹配对应元素
- (继续处理)
有一说一,爬取速度确实很慢。。。肉眼可见的慢,只有*M/h
爬虫总结
Selenium 还有一些有趣的东西还有待挖掘,下次再玩,先总结一下
-
实习的最初阶段,我们收到了数据采集的任务,由于我本身对爬虫方面比较感兴趣,所以我向相关人员提出意向接下这份任务。
-
采集的最初阶段是十分困难的,因为本身对爬虫的了解也只是停留在兴趣层面,没有涉及到对整个网站爬取数据的具体步骤。同时,各大网站对爬虫也采取了很多不同的反爬机制,心理压力也是非常大。后来我跟着网上的一些博客学习,浏览了feapder等爬虫框架的官方文档,我开始逐渐恢复自信,也相信自己能够一点点实现他们提出的数据采集要求。
-
在爬取某新闻网站时,遇到了许多困难,比如一开始不知道以什么方式大量爬取,或者说以什么路径大量爬取。一开始想着用深度遍历的思想,一层一层解析下去,但是这样会导致大量的重复爬取。好在发现了该新闻网站有专门的日历,可以查看不同日期下的新闻,同时URL呈现一定规律,可以实现批量爬取。
-
虽然数据已经可以批量爬取了,但速率真的非常低,平均下来每分钟只能爬500KB。接下来我开始了漫长的加速过程。试过很多很多办法,也遭遇了很多碰壁,比如我尝试用异步线程去分布式爬取,但我自己使用的feapder框架本身就是协程异步架构的,再用异步线程会导致效率下降。再比如我尝试加快发送请求频率,虽然短时间速度上去了,但没过多久我的IP就被该网站设为异常,需要手动解除。
-
但好在最终找到了方法,我先是优化了IO流,减少文件读写的次数,累计一篇数据再按规范写入;接着采取物理意义上的分布式爬取,下班后利用办公室的多台电脑进行按月爬取,效率确实得到了显著提升。
-
紧接着是对某某日报的数据采集,这次一开始就发现了能够按时间爬取,但可惜的是,20年之前的数据就不能以游客身份访问了,因此只能爬3年数据。由于和某新闻网站类似,都是静态网页,且以年份为序,不再赘述。值得一提的是,由于是报刊类的网站,它本身会带有很多版号或者副刊,即一期可能会在不同领域有对应的副刊或者其他版,因此需要去爬取对应的链接,实现第二层解析。
-
数据采集获得阶段性成果后,我就开始了数据清洗的工作,由于数据都是我自己采集的,格式也是我自己设计好的,所以清洗的过程不是很难,只要做到txt转json,然后过滤掉一些内容很短的垃圾数据即可。数据去重也比较简单,比较URL就能删去重复项。
-
最难的还是采集某百科的数据,首先没有公开词条库让我去批量访问,其次网页本身是动态渲染的,直接使用feapder的AirSpider发送请求获取的是未解析的JS源码。对于词条数据,我申请了清华的开放词条数据,然后提取出词条向某百科发送请求。对于动态页面,我采用了selenium的webdriver来模拟人为访问过程,同时使用了BeautifulSoup来进行页面解析。因为拿到的是String内容,而不是之前XPATH能解析的HTML,所以我使用了re库来进行正则匹配获取对应的文本。所幸最终可以成功提取他们想要的百科数据,但模拟人为访问注定要降低速率,爬一整天也就10MB左右,至少在我工作期间是不能采集完成了,不过对我来说,写出相应脚本就算完成任务了。
-
8月底,我结束了数据采集的所有任务,上传了相应的数据集和脚本文件。在写脚本的README.md说明文档时,我还是非常开心的,看着一个个脚本就感觉收获一个个知识。诚然,整个过程可能不是那么顺畅,但好在最终的结果是好的,我学到并掌握了一门新的技术,一门很早就感兴趣但一直没动力深入学习的技术。事实证明,项目才是推动学习的最佳方式,尤其是对于我们这类计算机学生,项目给予的压力,一边给我们带来痛苦,另一边也促使我们在压力下快速进步。
完结撒花!(虽然亚运大概率接着干...
参考文档
---Selenium及总结&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/01/16/20240116-200107.jpg&summary=完结撒花?复盘一下而已 ( “▔□▔ )){kind=link}
---Selenium及总结&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/01/16/20240116-200107.jpg&desc=完结撒花?复盘一下而已 ( “▔□▔ )){kind=link}
 微信
微信
 支付宝
支付宝