
从0开始写操作系统(一) ---前置知识
从0开始写操作系统(一) ---前置知识
现在是周末早上,昨天晚上刚感叹要早睡,现在就开始感叹要早起。
尤其是周末,早上的时间确实很宝贵
这次由于课程兴趣,想尝试从0开始写操作系统,后面可能还会有从0开始写编译器
至于为什么开始搞底层,开发太卷了,而且我关注的好多博主都失业了。。。
(一天后撤回上一句)还是开发吧 Q A Q
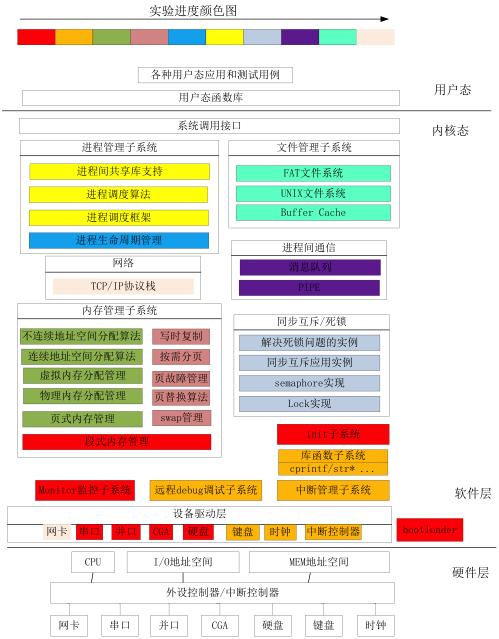
概览
整个实验的步骤
- 启动操作系统的bootloader,用于了解操作系统启动前的状态和要做的准备工作,了解运行操作系统的硬件支持,操作系统如何加载到内存中,理解两类中断--“外设中断”,“陷阱中断”等;
- 物理内存管理子系统,用于理解x86分段/分页模式,了解操作系统如何管理物理内存;
- 虚拟内存管理子系统,通过页表机制和换入换出(swap)机制,以及中断-“故障中断”、缺页故障处理等,实现基于页的内存替换算法;
- 内核线程子系统,用于了解如何创建相对与用户进程更加简单的内核态线程,如果对内核线程进行动态管理等;
- 用户进程管理子系统,用于了解用户态进程创建、执行、切换和结束的动态管理过程,了解在用户态通过系统调用得到内核态的内核服务的过程;
- 处理器调度子系统,用于理解操作系统的调度过程和调度算法;
- 同步互斥与进程间通信子系统,了解进程间如何进行信息交换和共享,并了解同步互斥的具体实现以及对系统性能的影响,研究死锁产生的原因,以及如何避免死锁;
- 文件系统,了解文件系统的具体实现,与进程管理等的关系,了解缓存对操作系统IO访问的性能改进,了解虚拟文件系统(VFS)、buffer cache和disk driver之间的关系。
总结:
-
启动
-
内存
- 物理
- 虚拟
-
内核线程,用户进程
-
处理器
-
进程间通信(同步互斥)
-
文件系统
前置知识
环境搭建
Ubuntu 22.04
- 更新 vim
sudo apt update
#或 sudo apt upgrade vim
-
安装 build-essential
一个封装好的工具包,包含了 gcc , make , C标准库等工具
sudo apt-get install build-essential
-
安装QEMU
QEMU用于模拟一台x86计算机,让ucore能够运行在QEMU上
sudo apt-get install qemu-system
GCC
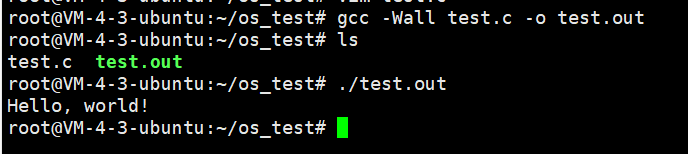
简单的gcc编译示例
/*test.c*/
#include <stdio.h>
int
main(void)
{
printf("Hello, world!\n");
return 0;
}
编译
gcc -Wall hello.c -o hello
-Wall 和 -o 都为编译选项
-Wall : 开启编译器几乎所有常用的警告
-o : 生成可执行文件
内嵌汇编
以下示例均以X86汇编的AT&T语法为准
-
GCC基本内联汇编
-
示例
asm( "pushl %eax\n\t" "movl $0,%eax\n\t" "popl %eax" );-
基本的比较简单,暂不介绍,给出一份GPT解释:
-
它使用 pushl 指令将寄存器%eax的值推送(压入)到堆栈(栈顶),即将%eax的当前值保存在堆栈上。
-
接下来,它使用 movl 指令将常数值0加载到寄存器%eax中,将%eax的值设置为0。
-
最后,它使用 popl 指令将先前保存在堆栈上的值弹出(出栈)到寄存器%eax中,这将恢复%eax的原始值,即之前保存的值。
-
-
tips:这里的 l 都是立即数的意思
-
-
-
GCC扩展内联汇编
-
示例1
#define read_cr0() ({ \ unsigned int __dummy; \ __asm__( \ "movl %%cr0,%0\n\t" \ :"=r" (__dummy)); \ __dummy; \ })解释如下:
#define read_cr0() ({:这是一个C语言宏的定义,名为read_cr0,它没有参数。unsigned int __dummy;:在宏中定义了一个名为__dummy的无符号整数型局部变量,用于存储从控制寄存器 CR0 读取的值。__asm__(:这是内联汇编块的开始标记,表示以下部分包含汇编代码。"movl %%cr0,%0\n\t":这是一条汇编指令,使用movl指令将 CR0 寄存器的内容移动到输出操作数%0中。%%cr0表示访问 CR0 寄存器的值,%0表示输出操作数。:"=r" (__dummy));:这是汇编约束(constraint)部分,它告诉编译器如何处理输出操作数%0。"=r"表示将%0分配给一个通用寄存器,并且%0的值将被存储在__dummy变量中。__dummy;:在宏的最后,返回__dummy变量的值。
这段代码的作用是使用汇编指令读取控制寄存器 CR0 的值,然后将该值存储在
__dummy变量中,并最终返回这个值。通常,读取控制寄存器的值是为了访问系统的某些配置信息或状态。这个宏可以在C代码中以函数调用的方式使用,以读取和访问 CR0 寄存器的内容tips :
- 这里的%%cr0 是为了防止与C发生冲突(参考printf格式化输出)
- 这里的%0表示输出操作数(%0是指定的占位符) , 正常来说 %1,%2 都表示输入操作数
- 1, 2 表示常数立即数
-
示例2
int count = 1; int value = 1; int buf[10]; void main() { asm( "cld\n" // 清除方向标志位 (Clear Direction Flag),确保字符串操作从低地址向高地址写入 "rep\n" // 重复执行指令 "stosl" // 将值写入内存 (Store Doubleword in String) : : "c" (count), "a" (value), "D" (buf[0]) // 输入和输出操作数 : "%ecx", "%edi" // 选择受影响的寄存器 ); }解释如下:
int count = 1;和int value = 1;:这两行定义了两个整数变量count和value,并初始化它们的值为1。int buf[10];:这行定义了一个整数数组buf,包含10个元素。asm(...):这是内嵌汇编的开始。内嵌汇编允许在C代码中嵌入汇编指令。"cld\n":这是汇编指令,它执行cld操作,清除了方向标志位,确保后续的字符串操作从低地址向高地址写入数据。默认情况下,方向标志位是设置的,可能导致字符串操作反向执行。"rep\n":这个部分是rep前缀,它用于重复执行下一个指令。"stosl":这是stosl汇编指令,它用于将一个双字(32位整数)存储到目的地内存中。在这个上下文中,它用于将value存储到buf[0]处。- 输入操作数:在
asm语句的冒号后面,有一个用于输入操作数的部分。它告诉编译器如何将C变量映射到汇编操作数。例如,"c" (count) 表示将C变量count映射到汇编操作数%ecx,"a" (value) 表示将C变量value映射到汇编操作数%eax,"D" (buf[0]) 表示将C变量buf[0]映射到汇编操作数%edi。 - 受影响的寄存器:在冒号后的第三个部分列出了受影响的寄存器。
%ecx和%edi是受到汇编代码影响的寄存器。
它给出的汇编如下:
movl count,%ecx movl value,%eax movl buf,%edi #APP cld rep stosl #NO_APPtips:一开始觉得教程有问题,来回问GPT后懂了一点(3.5真的很差劲啊,有钱一定要升4,QAQ)
- 受影响的寄存器中没有写 eax 这是因为 eax 存在的目的就是为了让 value 存入 buf[0],而不是为了让 eax 输出
- count 其实是用到了 这和 stos 本身特性有关 ,他会执行 ecx 上的次数
-
附上一份通用寄存器表
- EAX:累加器
- EBX:基址寄存器
- ECX:计数器
- EDX:数据寄存器
- ESI:源地址指针寄存器
- EDI:目的地址指针寄存器
- EBP:基址指针寄存器
- ESP:堆栈指针寄存器
Makefile
这和我的实习内容相关,教程里没有明确写出明确步骤
我简单归纳一下:
目标文件: 编译器 编译选项 源文件
命令(脚本封装) :
具体实现
这里的命令可以通过 make 命令 进行脚本调用
提供一份不错的参考博客
gdb
调试的话,我这提供一份教程给的参考表
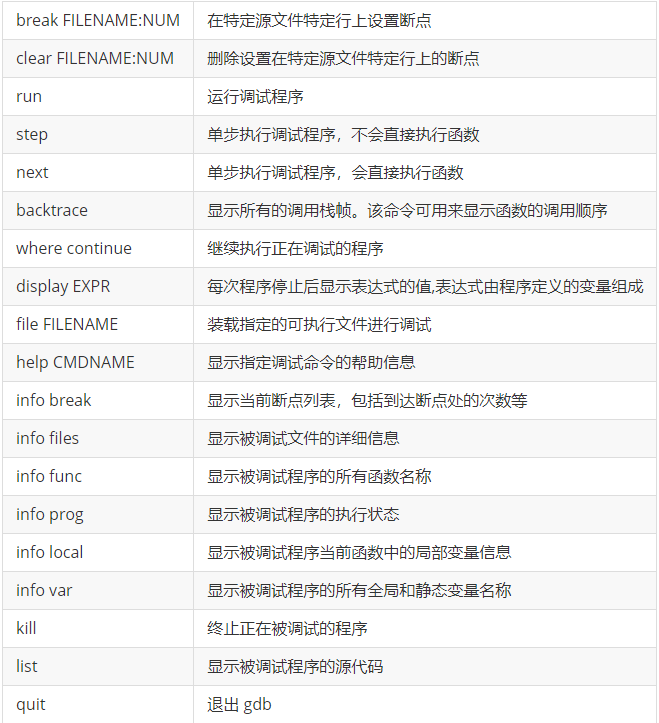
具体的其实没必要记特别多,常见的 run,start,step,quit,backtrace之类的会用就行。
Tips:
-
break 的使用既可以 设置 数字如: break 2 ;也可以设置为某个函数,如:break function
-
但这些的前提都是,可执行文件编译时,需要带上 -g 编译选项 ,同时,进入gdb时需要先
后续就跟着OS实践课走下去吧,课外还是学 JAVA 和 算法 为主
G,还有好长的一条开发路
参考文档
一本非常厉害的教程操作系统实验
 ---前置知识&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/01/16/20240116-200047.jpg&summary=在OS实践课开始前,做点准备工作){kind=link}
 ---前置知识&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/01/16/20240116-200047.jpg&desc=在OS实践课开始前,做点准备工作){kind=link}
 微信
微信
 支付宝
支付宝