
OS学习笔记 (一)--- 文件系统
OS学习笔记 (一)--- 文件系统
文件和文件系统
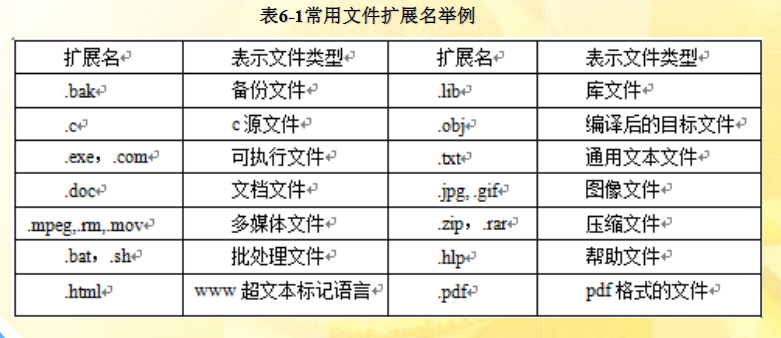
文件结构和存取
知识点:逻辑结构、物理结构、文件存取
逻辑结构
有结构文件就像是数据结构,比如栈、堆或者队列
无结构文件就像数组、链表
有结构文件可以由不同的无结构文件构成
-
有结构文件
-
若干条记录构成(记录式文件
适用于大量的数据结构和数据库
(表格)
-
顺序文件、索引文件、顺序索引文件
对应了 数组、带指针的索引表、指针指向数组中的某一个的索引表(不一定按顺序指向
-
-
无结构文件
-
由一组相关信息组成的有序字符流(流式文件
使用读写指针访问
(记事本)
-
物理结构
-
连续文件(顺序文件
-
优点:快、随机存取
缺点:文件修改困难、磁盘空间出现碎片
举个例子:如果文件大小发生变化,需要移动文件以维护连续性,这可能会导致大量的数据移动和碎片整理。此外,连续文件在存储空间分配方面可能不够灵活,特别是在文件频繁增长或缩小的场景下。
-
-
链接文件(分散存储
-
隐式链接(链表嵌套,和顺序存取没啥差别
-
显式链接
链接表(FAT):逻辑磁盘中设立一张表,以物理盘块号为序,表项内容为指向某文件的下一盘块指针
优点:检索速度快、随机存取
缺点:占用内存空间大、表大时,存取效率低
-
-
索引文件
- 单级索引、多级索引、混合索引
文件存取
连续文件适用于顺序存取且不常修改
链接文件适用于顺序访问的文件
索引文件既可以顺序访问也可以随机访问
文件目录管理
目录是FCB的有序集合,
FCB
用于描述和控制文件,保存相应的系统管理文件信息,与文件一一对应
(内部包含文件名、用户名、文件类型、时间、日期等)
索引节点
引入原因:
- 由于查找文件时的启动磁盘I/O操作次数大((N+1)/2)
- 检索的本身并不需要文件内容,只需要文件名即可
分类:
-
磁盘索引节点:包含了除了文件名以外的所有文件属性信息
-
内存索引节点:打开文件时创建的索引节点,并增加状态、访问次数、链接指针等参数
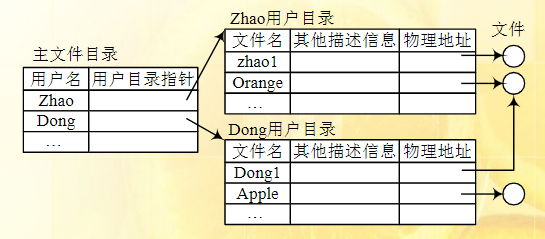
目录结构
单级、两级、多级
两级结构图如下
多级目录如下
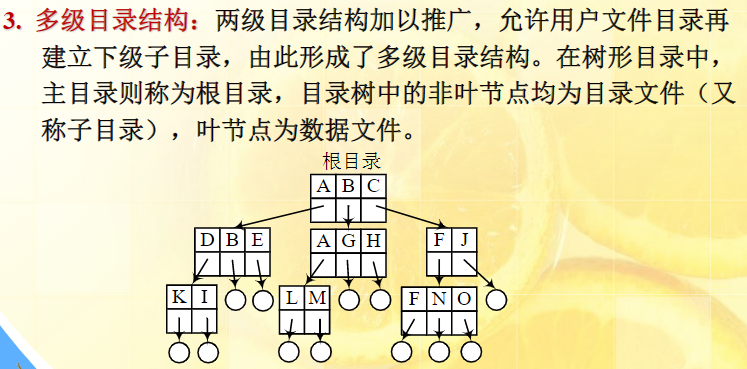
(和树差不多)
优点如下:层次清楚、允许重名、速度快
检索技术
线性、HASH
一个顺序查找,一个新建Hash表,如果Hash冲突就在此Hash值上加一个新索引值
存储空间管理
-
空闲表法,所有空闲分区都建立一张空闲表
其中包含了空闲盘块号和相应的空闲盘块数,按顺序排列
序号 第一空闲盘块号 空闲盘块数 1 10 7 2 20 5 ... ... ... -
空闲块链表法,空闲盘块存放指针指向下一空闲盘块,形成一个链表
空闲盘区链,链接的是一个个连续的空闲盘块
-
位视图:对应盘块0为空闲,1为忙碌
-
成组链接法:
最后一组一般设置(每组个数-1)留一位作为结束符,通过个数作为tag,获取下一个空闲组的地址
利用空闲盘块栈进行分配和回收,分配时要检查是否到栈底(0),回收时要检查,栈满了没
文件共享和文件保护
文件软链接和硬链接的区别
命令上: 软连接 ln -s 硬链接 ln
ls -il 展示时: 软链接的文件是链接文件,而且inode号不同;硬链接生成的文件类型与源文件一致,且inode号一致,说明是同一个文件
链接计数不同:因为链接计数本身就指的是,有多少硬链接指向该文件
文件大小不同:硬链接与源文件大小相同,符号链接生成的文件只有文件名大小(“file”->4B)
硬链接不能跨卷链接,不能创建目录链接
软链接相当于创建了一个 快捷方式
不管是修改软链接的文件还是硬链接的文件,源文件都会被修改
区别在于,一个是对源文件的路径引用,一个是对源文件数据本身的引用
文件保护
-
编写访问控制矩阵

-
编写访问控制表
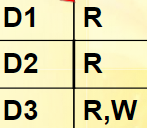
-
编写用户权限表

分别是访问控制矩阵按行(用户)生成用户权限表,按列生成访问控制表
磁盘调度
磁盘物理结构如下:
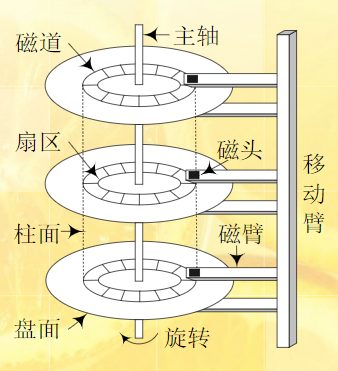
解释一下从大到小的结构:
首先是盘面号(磁头号)就是横向切了一个横截面
然后是柱面号(磁道号)就是对应的某个圆环
然后是扇区号,就是对应的圆环中的某个扇区

标准: LBA = (C * 磁头数 + H) * 每磁道扇区数 + (S - 1)
存储容量=磁头数*柱面数*扇区数
磁盘访问
磁盘访问时间=寻道时间+旋转延迟+传输时间
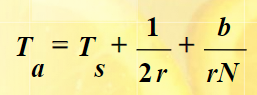
Ts=m*n+s (移动一条磁道所需时间*磁道数+启动时间)
磁盘调度算法
移臂调度、旋转调度
多个同心圆,先访问哪个|当前同心圆先访问哪个扇区
1. 先来先服务(FCFS, First-Come First-Served)
这是最简单的调度算法,处理请求的顺序完全取决于请求到达的顺序。它不考虑磁头当前的位置或请求的位置,因此可能不是最有效的算法,特别是在多个请求竞争时。
2. 最短寻道时间优先(SSTF, Shortest Seek Time First)
SSTF选择磁头当前位置最近的请求来服务,以此来减少寻道时间。这种方法可能导致“饥饿”现象,即一些距离磁头较远的请求可能会等待很长时间才被处理。
3. 电梯算法(SCAN)
电梯算法,也称为扫描算法,磁头会像电梯一样在一个方向上移动,满足所有的请求,直到没有更多的请求为止,然后它转向并处理另一个方向上的请求。这种方法比SSTF更公平,因为它防止了饥饿现象。
4. 循环扫描(C-SCAN, Circular SCAN)
C-SCAN是SCAN的变体,它在到达一个方向的尽头后立即跳转到另一端继续服务,而不是改变方向。这保证了所有的请求都会在有限的时间内得到服务,提供了更均匀的等待时间。
5. N-Step-SCAN / FSCAN
这些是SCAN算法的变种,在它们中,磁盘请求被分成若干组(N步),每次只有一个组的请求被服务。这可以平衡即时性能和整体性能。
总结一下,个人感觉电梯算法是最合适的,存在即合理
C-Scan、N-SCAN和FSCAN都是 SCAN的变种,主要目的是为了 减少极端情况带来的误差
以实现平衡性能
有一篇非常好的文章介绍了各类调度算法
是我关注的博主写的,欢迎各位去浏览
Linux文件系统
VFS虚拟文件系统
磁盘方面

网络方面
NFS、Coda、AFS等
特殊文件系统
/proc /sys (存储在内存)
实现模型
应用层:应用程序中使用 标准文件系统调用函数 :open() read()write()close()
虚拟层:VFS根据目录项获取对应的索引节点 调用sys_open()等内核函数 (包含目录项缓存、索引节点缓存、页缓存)
实现层:文件系统(Ext2等文件系统)调用对应的文件操作函数->缓冲区缓存读写操作,并与驱动器交互
主体对象
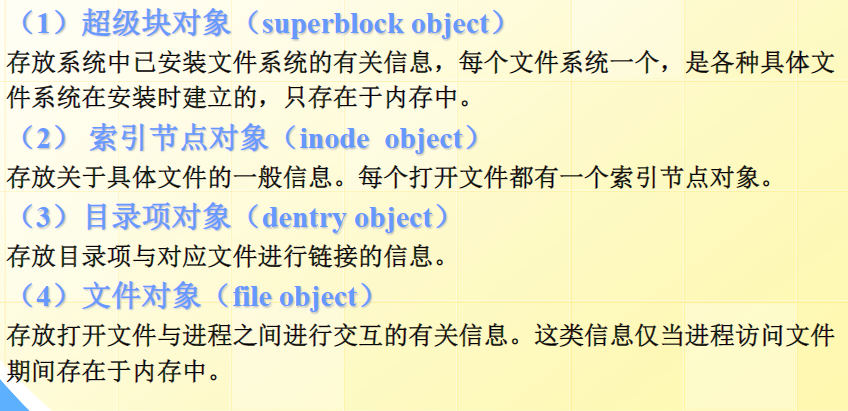
超级块存储了一整个文件系统的信息,保存了文件系统的挂载点和根目录、管理了索引节点表
读取和修改文件时
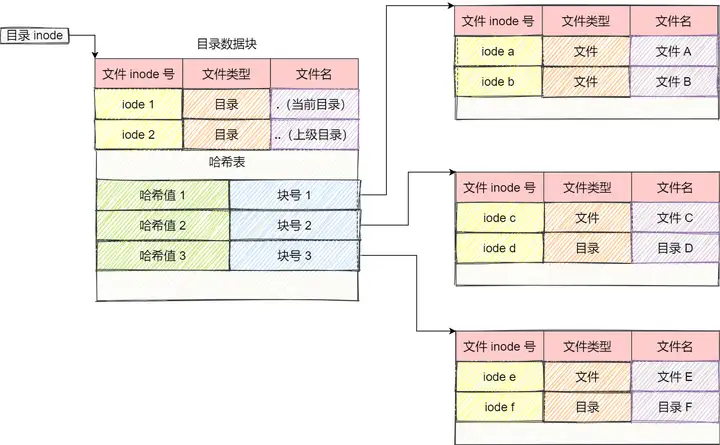
1、我们首先根据文件名,找到这个文件的Inode-no(节点号)。 目录项 2、当我们找到个文件的Inode-no时,就会根据这个number数在inode-table中找到对应的条目。索引节点表 3、现在要我们看一看inode-table中的信息:从左到右依次是:节点数、文件类型、文件的权限、硬链接数、用户ID、组ID、文件的大小、时间戳记,最后为指向硬盘上存放数据的数据块的指针。
文件I/O
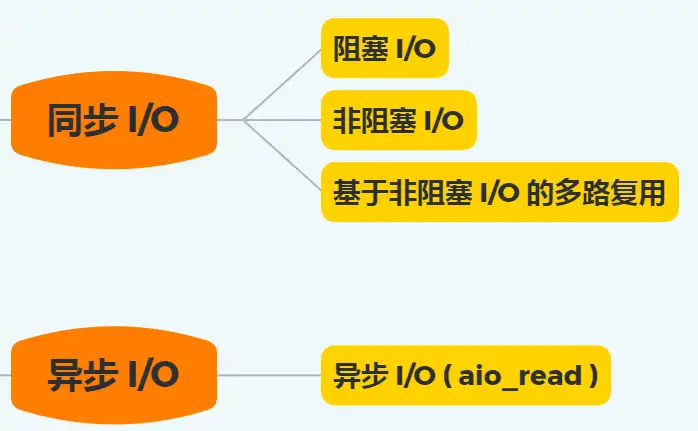
博主的奇妙比喻
阻塞就是,我请求接你,但是你还没好,我在你家门口等你
非阻塞就是,我请求接你,你还没好,我先回来,过会儿再来,一直循环
非阻塞多路复用就是,我请求接你,你还没好,我先回来,你好了跟我说一声,我再过去
异步IO就是,我请求接你,你还没好,你说你自己走过来
参考文章
终于实现了Typora的阿里云OSS,很早就烦Typora的图片保存在本地,导致博客上传时,需要一张张图片上传,很麻烦。
有需要的小伙伴可以查看教程: Typora+阿里云OSS实现图片上传云端
--- 文件系统&pics=/upload/tyler-lillico-zbZQQ1a2WWg-unsplash.jpg&summary=){kind=link}
--- 文件系统&pics=/upload/tyler-lillico-zbZQQ1a2WWg-unsplash.jpg&desc=){kind=link}
 微信
微信
 支付宝
支付宝