
异构计算笔记
异构计算笔记
GPU基础知识
GPU采用的是哈佛架构,数据与指令分开,虽然内存被划分成了不同部分(如纹理内存等)但这些都是数据而不是指令
N卡GPU微架构演变史
Kepler架构: FP64单元和FP32单元的比例是1:3或者1:24;GPU型号K80。
Maxwell架构: FP64单元和FP32单元的比例下降到了只有1:32;GPU型号M10/M40。
Pascal架构: 这个比例又提高到了1:2(P100)但低端型号里仍然保持为1:32,型号Tesla P40、GTX 1080TI/Titan XP、Quadro GP100/P6000/P5000
Votal架构: FP64单元和FP32单元的比例是1:2;FP32 和 INT32可以同时处理;型号有Tesla V100、GeForceTiTan V、Quadro GV100专业卡。
Turing架构: 一个SM中拥有64个半精度,64个单精度,8个Tensor core,1个RT core。
Ampere架构: 该架构作为一次设计突破,在8代GPU架构中提供了NVIDIA公司迄今为止最大的性能飞跃,统一了AI培训和推理,并将性能提高了20倍。A100是通用的工作负载加速器,还用于数据分析,科学计算和云图形。
Hopper架构: NVIDIA Hopper架构是NVIDIA在2022 年3月推出的GPU 架构。 这一全新架构以美国计算机领域的先驱科学家 Grace Hopper 的名字命名,将取代两年前推出的 NVIDIA Ampere 架构。
问题小结
-
影响GPU运行速率的硬件参数:
1. 核心数量(CUDA Cores / Stream Processors)
- 影响因素: GPU 上的核心数量类似于 CPU 的核心数量,但数量通常更多。更多的核心意味着能够同时处理更多的操作。
- 性能影响: 核心数量越多,GPU 的并行处理能力越强,从而提高了其总体计算能力。
2. 核心频率(Clock Speed)
- 影响因素: 核心频率是指 GPU 核心执行操作的速度。
- 性能影响: 频率越高,单位时间内能执行的操作次数越多,从而提高处理速度。
3. 内存大小和类型(GPU Memory)
- 影响因素: GPU 内存用于存储进行处理的数据。内存的大小和速度对性能有重要影响。
- 性能影响: 更大和更快的内存允许处理更大的数据集,减少了数据在 GPU 和主内存之间的传输时间。
4. 内存带宽(Memory Bandwidth)
- 影响因素: 内存带宽是 GPU 可以读写内存的速度。
- 性能影响: 带宽越高,数据传输速度越快,有助于提高处理大量数据时的效率。
5. 缓存大小(Cache Size)
- 影响因素: 缓存是 GPU 上的一小块快速存储区域,用于临时存储频繁访问的数据。
- 性能影响: 更大的缓存可以减少对主内存的访问次数,提高处理速度。
6. 架构优化(Architecture)
- 影响因素: 不同的 GPU 架构可能会对特定类型的计算任务进行优化。
- 性能影响: 针对特定任务优化的架构可以显著提高在这些任务上的性能。
7. 能源效率(Power Efficiency)
- 影响因素: 高能效的 GPU 能在消耗更少能源的情况下提供较高的性能。
- 性能影响: 能效影响了 GPU 在持续负载下的性能稳定性和持续性。
可以根据Nvidia 提供的白皮书进行对比
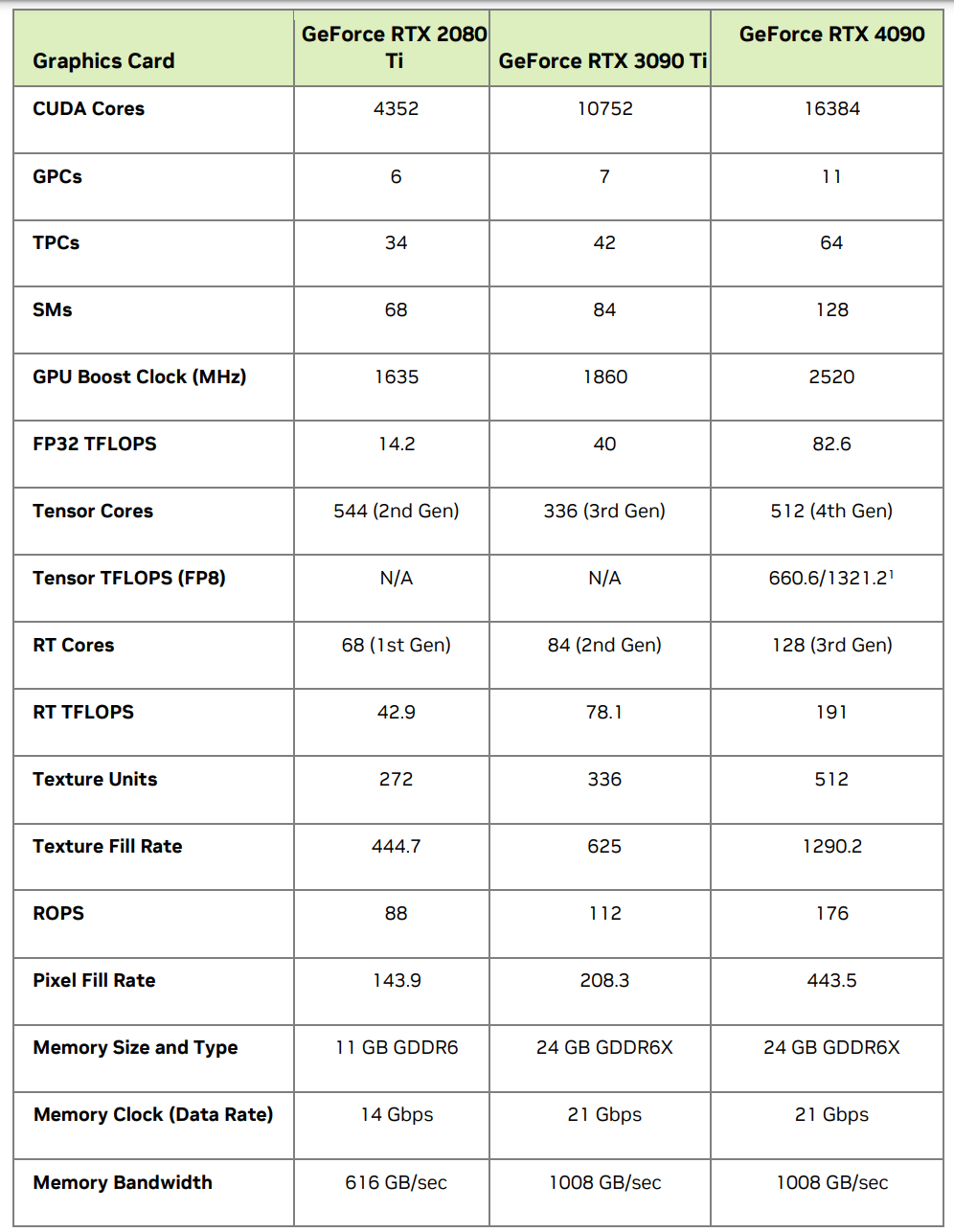
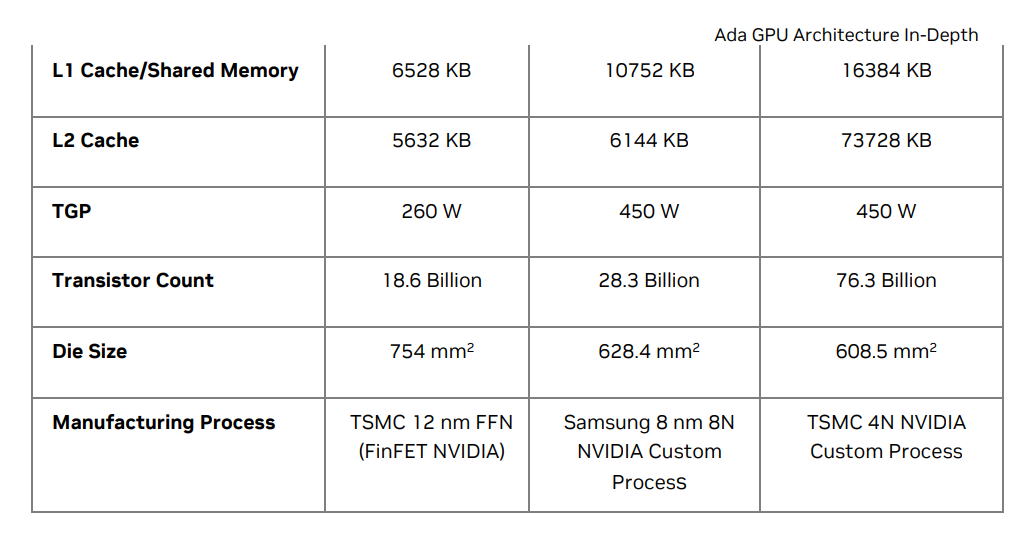
-
内存的多级结构
1. 寄存器(Registers)
- 特点: 寄存器是最快速且最接近计算核心的存储区域。每个线程都有自己的寄存器。
- 用途: 用于存储线程执行中的临时变量。
2. 共享内存(Shared Memory)
- 特点: 共享内存是一种较快的内存,由同一块处理器(如同一SM,流式多处理器)上的线程共享。
- 用途: 用于线程之间的数据共享和协作。
3. L1 缓存(L1 Cache)
- 特点: L1 缓存是一种快速的缓存,位于每个核心或SM旁边,与共享内存有时是统一的。
- 用途: 主要用于缓存本地数据和减少对更低级内存的访问次数。
4. L2 缓存(L2 Cache)
- 特点: L2 缓存较L1缓存慢,但容量更大,是全局的,被所有的处理器核心共享。
- 用途: 用于减少对全局内存的访问。
5. 全局内存(Global Memory)
- 特点: 全局内存容量最大,但访问速度相比于上述内存要慢得多。
- 用途: 用于存储需要长时间存储或由多个核心访问的数据。
6. 常量内存(Constant Memory)和纹理内存(Texture Memory)
- 特点: 这些是特殊类型的缓存内存,用于优化特定模式的访问(例如,当多个线程访问相同的数据时)。
- 用途: 用于存储不经常变化的数据(常量内存)或专门的图形数据(纹理内存)。
7. 本地内存(Local Memory)
- 特点: 当寄存器不足时,本地内存用于存储线程的私有数据,但它实际上是全局内存的一部分,速度较慢。
- 用途: 用作寄存器溢出的备份存储。
上面的白皮书中也展示出了 对应的L1缓存和L2缓存,值得注意的是,L1有时候是和共享内存统一的。此时两者共享的是同一块物理内存,并且有时候可以人为划分
在某些 NVIDIA GPU 架构中,开发者可以选择分配更多的内存给共享内存,以便更高效地进行线程间通信,或者分配更多给 L1 缓存,以便更有效地缓存全局内存访问。
什么是Tensor Core?
SM中的特殊计算单元,可以用来加速矩阵乘法的计算、进行混合精度计算
nvcc
nvcc本身就是多个编译器的集合(gcc、cicc、ptxas、fatbinary)
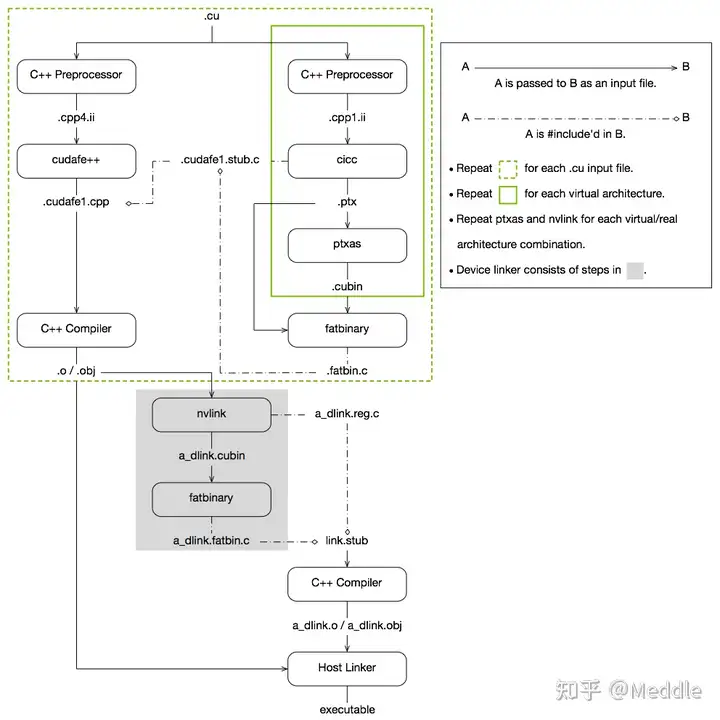
分为离线编译和即时编译
离线编译是绿色虚框、在编译预处理阶段,会将cuda代码分为主机端和设备端
nvcc的 dryrun 编译选项可以查看编译过程经历了哪些步骤
cicc获取gcc预处理的代码,然后将其中的设备代码生成PTX(.ptx) CUDA的虚拟架构汇编文件
ptxas将生成的ptx文件根据真实架构编译为(.sm_xx).cubin文件
fatbinary将不同的虚拟架构生成的.ptx文件和.cubin合并在一起生成.fatbin.c文件
这里一定程度上实现了硬件隔离机制,因为GPU的架构是不断迭代的,但是cicc只需要将对应的设备端代码转换成 虚拟架构的汇编文件即可
新架构的上线,只要修改ptxas和对应的驱动程序
fatbinary会根据不同的真实架构与虚拟架构进行整合,这样cuda程序就可以在不同架构上跑了
然后gcc会再进行一次预处理,cudafe++将主机端代码提取出来
与设备端的.cudafe1.stub.c(由刚才的.fatbin.c组成)结合
得到.cudafe1.cpp文件,
再进行 预处理、汇编、编译生成.o目标文件(主机端)
在最后的链接过程中,nvlink将不同device code的.o文件 定位到真实设备上,生成.sm_xx.cubin文件
同时生成 reg.c 中间件,用来记录寄存器、内核函数、设备端代码使用等情况(以及link.stub)
接着使用fatbinary将cubin文件生成.fatbin.c文件
与之前的中间件 .reg.c文件、link.stub(链接中间件)结合 使用gcc生成最终的.o目标文件(设备端)
g++链接主机端和设备端目标文件生成可执行二进制文件
cu-bridge
主要组成部分:cucc、conf.json、cmake_module、cmake_maca、make_maca、gomxccbin
以及所有的头文件
流程图
总体编译流程(红色部分才是cu-bridge)(注意,此处的mxcc代指类nvcc编译器组)
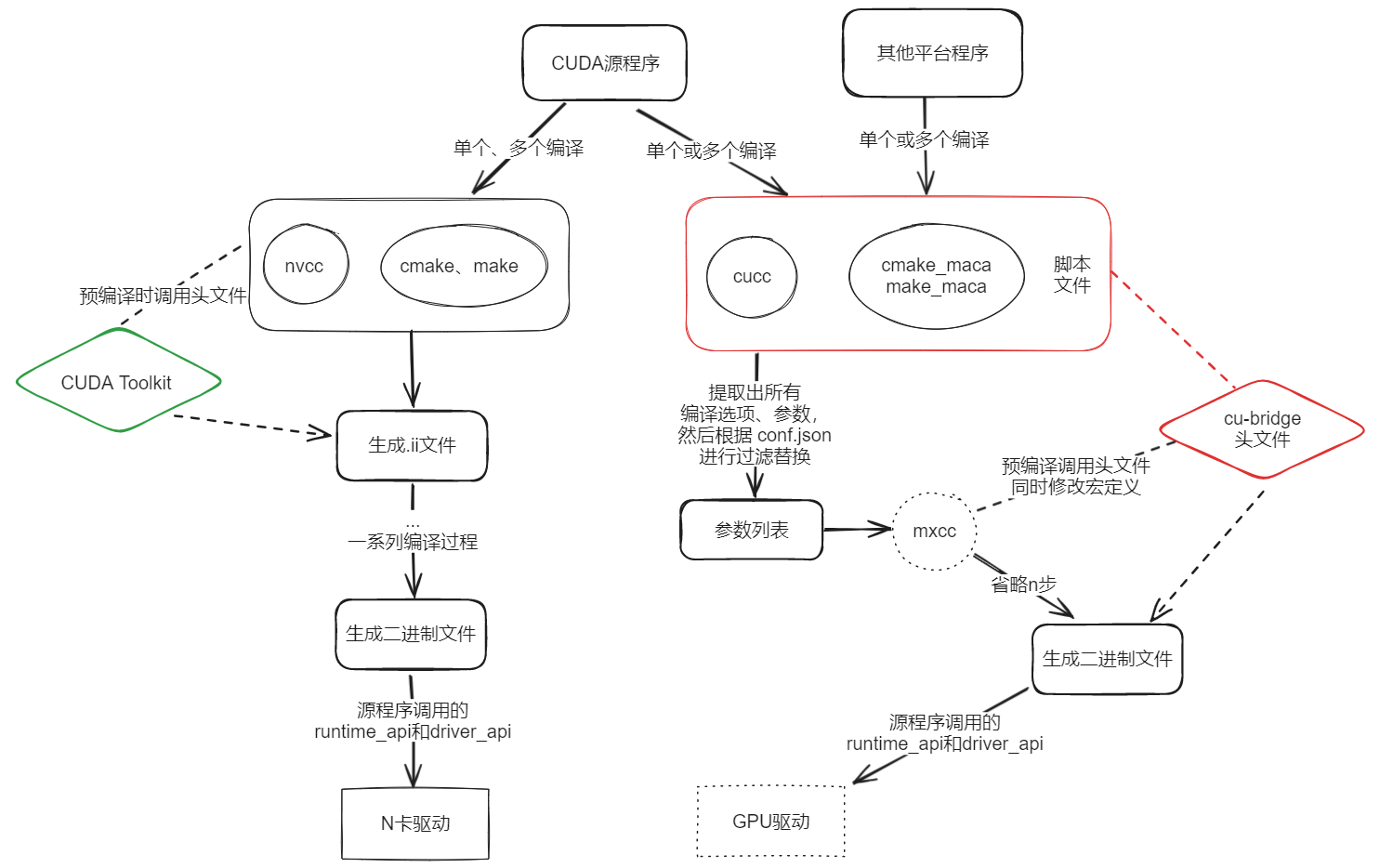
我的主要工作其实并不涉及主体框架的设计和脚本编写、这次复盘只是为了搞懂整个项目
原理流程已经很清晰了:
左边是CUDA程序正常的编译过程,可以直接在N卡上跑;右边是在其他GPU上跑的情况
问题在于这一套项目的组成前提是:
-
必须有自己的一套GPU编译器,设计的像上面的nvcc一样完善,CUDA Toolkit 提供的只有二进制文件,想要在自己的GPU上跑,必须设计好相应的编译器,提供对应的二进制文件
-
必须有一套成熟的GPU驱动文件组,像N卡驱动一样(下图为驱动核心组件)

实现原理
然后我们再聊回cu-bridge干了什么
首先,考虑到用户体验,要尽量像nvcc一样使用,那么提供一个cucc(看上去像nvcc的脚本)来运行编译命令
比如
nvcc -o vectorAdd vectorAdd.cu此时我也调用命令cucc -o vectorAdd vectorAdd.cu想要实现一样的效果,该怎么做?
首先将后面的编译选项,源文件,文件名称等参数提取出来,然后再将参数传回给类nvcc编译器组
根据上文提到的nvcc编译过程,我们可以知道,nvcc并非单一的编译器,而是由多个编译器、中间件组合而成,那么当我们拥有了一套类N卡驱动的GPU驱动时,只要将源程序中的N卡runtime-api、driver-api 改成自己GPU的相应API即可。
我们该如何做到这一点呢?
cu-bridge提供了一种方案,就是修改所有CUDA Toolkit中头文件的宏定义,然后重写一遍对应函数(这里的对应函数是和CUDA对应的同时,和底层驱动对应)
其实所谓的重写和修改宏定义一样,就是换个函数名,关键在于底层的驱动要实现和原函数一样的效果
所以一阵剖析下来其实cu-bridge并没有干什么特别伟大的事情,但事实是这提供了一条兼容的路径,A卡的做法就不是兼容,而是类比CUDA开创一个自己的软件平台(ROCm),面对CUDA程序使用工具(HIP)进行转换,换成自己的程序。
怎么说呢,CUDA太成熟了,市场份额占有率高,ROCm和HIP的存在比较尴尬
而且这条兼容的路径不仅可以兼容CUDA,同样也可以兼容ROCm,关键在于底层的驱动实现和驱动优化
版本迭代(脚本)
其实我接手这个开源项目时,他已经差不多到第二代了。
回顾一下第一代的话,就是实现了刚才提取参数列表的主体流程
第二代比第一代完善了很多部分,支持了--options-file选项文件
增强了宏定义处理、增加了警告处理
添加了编译模式选项(-c 仅编译;-dc 仅链接;-o 编译并链接)
增加LDFLAGS选项(环境变量:链接库文件、添加目录到库搜索路径等)
增加gcc工具链,来直接处理非CUDA程序(处理CUDA主机端是在编译器进行,而不是脚本)
第三代其实算不上第三代,只是开源出了go脚本,辅助CUDA编译过程,它接收到cucc处理参数列表结束的命令,然后根据编译环境(或者硬件架构)删除(或替换)部分编译选项,最终将新的命令输出给cucc,然后执行。
版本迭代(仓库)
其实就是CUDA Toolkit中的各类头文件支持不断更新的过程,这个进度得看驱动开放(优化)的进度
。。。开源出来也没啥用,主要是驱动得跟上,不然换个函数名有什么用
附开源地址
CUDA编程
附上ZZK大佬的CUDA学习仓库,之前两次实习都遇到了这个项目,堪称CUDA编程启蒙
面试题
什么是SIMT
:单指令多线程,与计算机的SIMD类似,比如你调用一个核函数相当于单个指令派了多线程执行,可以提高计算效率。
SIMT具有以下SIMD不具备的性质:
- 每个线程有自己的指令地址计数器
- 每个线程都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径
什么是bank conflict,怎么解决
:并行计算在进行时,对共享内存的同一个存储体进行访问,会出现存储体冲突(bank conflict)
解决办法:常见的比如修改共享内存数据结构,例如你现在共享内存中的数组是
__shared__ int shared_array[32]; 由于GPU一般会将共享内存分为32个存储体,现在的数组都放在各自存储体内,如果进行同时访问某个存储体中的值,会出现bank conflict。理想状态下,同时访问0-31是不会出现bank conflict的。
但如果数组长度不为32而是64,访问0和访问32的线程同时出发访问会出现bank conflict。
此时可以使用填充,比如改数据结构为__shared__ int shared_array[33];这样之前在同一列(bank)的数据就不在同一列了。
详见具体参考资料
float4为什么读写global memory更快?
:因为获取4个float,使用float会发送4条LD.E指令,而float4会发送一条LD.E128指令,从而更快读取
(其实一旦读的量大起来也就没区别了)详见[博客
block能否被调度到不同SM上?
:不行,block就由一个SM负责,其中的所有线程的操作都由SM调度
Linux内核故障面经
-
Linux内核出现问题该怎么办
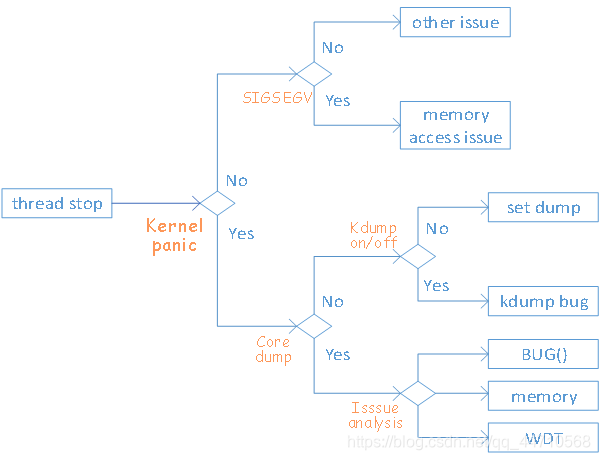
解释:
- 线程停止(Thread stop):
- 当一个线程因为某些原因停止时,可能会触发内核崩溃。
- 内核崩溃(Kernel panic):
- 如果是内核崩溃,接下来会检查是否生成了核心转储(Core dump)。
- 如果不是内核崩溃,可能会检查是否发生了
SIGSEGV(段错误信号)。
- 核心转储(Core dump):
- 如果有核心转储生成,接下来将进行问题分析(Issue analysis)。
- 如果没有核心转储,将检查
kdump是否开启。
- 信号
SIGSEGV:- 如果发生了
SIGSEGV,通常意味着有内存访问问题(Memory access issue)。 - 如果没有
SIGSEGV,则可能是其他问题(Other issue)。
- 如果发生了
kdump开启/关闭:- 如果
kdump功能开启,但没有生成核心转储,可能是kdump本身存在问题(kdump bug)。 - 如果
kdump没有开启,可能会考虑设置转储(Set dump)。
- 如果
- 问题分析(Issue analysis):
- 如果确认是
kdump的问题,或者核心转储已经生成,将进入问题分析阶段。 - 问题可能与内存有关,也可能是其他类型的
BUG。
- 如果确认是
- 用户态与内核态的概念
用户态是只能运行低特权程序的状态、内核态是可以运行高特权程序的状态
- 用户态和内核态的区别
权限不同、内核态对系统具有完全控制权,可以访问所有资源,执行任意指令;用户态只能访问有限的资源,执行受限的指令集
- 为什么要分用户态和内核态
提高安全性,不能让所有人都可以进入内核态随意执行指令。提高稳定性,用户态出错可以切换至内核态进行处理,内核态出错一般来说系统会崩溃。
- 用户态如何切换到内核态
系统调用、异常处理和中断(键盘输入属于中断)、硬件指令
系统调用的例子

异常的例子
当我的C语言程序访问非法内存,报段错误时,操作系统的异常处理机制会捕获这个异常,切换到内核态后会记录错误信息,并清除分配给用户的资源
力扣刷题临时站点
刷一道题吧,不刷心里痒痒
ID:104
二叉树最大深度
相当简单,昨天刚看过
nobugAC!!
但是可以优化,比如直接在函数内判断root是否为null,如果是就返回0,不是就返回子树最大深度+1;
我的:
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root)return depth(root);
return 0;
}
int depth(TreeNode* root){
if(!root->right&&!root->left)return 1;
if(root->right&&!root->left)return depth(root->right)+1;
if(!root->right&&root->left)return depth(root->left)+1;
if(root->right&&root->left)return max(depth(root->right),depth(root->left))+1;
return 1;
}
};
优化的:
class Solution {
public:
int maxDepth(TreeNode* root) {
if (root == NULL)
return 0;
else
return max(maxDepth(root->left), maxDepth(root->right)) + 1;
}
};
ID:226
翻转二叉树
嘿嘿,又是nobugAC!
爽,而且这次应该不用优化
answer:
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(!root){
return root;
}else{
TreeNode* tmp1=nullptr;
TreeNode* tmp2=nullptr;
if(root->left){
tmp1=invertTree(root->left);
}
if(root->right){
tmp2=invertTree(root->right);
}
root->left=tmp2;
root->right=tmp1;
}
return root;
}
};
换道图论或者DP,上上强度
ID:70
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
错了一次,已经想到迭代了,但是没搞清楚规律
后来列出几个就知道了
answer:
class Solution {
public:
int climbStairs(int n) {
if(n==1)return 1;
if(n==2)return 2;
int nums1[n];
int nums2[n];
int res[n];
nums1[0]=1;nums2[0]=0;res[0]=1;
nums1[1]=1;nums2[1]=1;res[1]=2;
int i=2;
while(i<n){
nums1[i]=res[i-1];
nums2[i]=nums1[i-1];
res[i]=nums1[i]+nums2[i];
i++;
}
return res[n-1];
}
};
ID:198

思路历程:一开始还没想出来,因为会隔一个受影响,后来还是老办法
枚举几个就熟悉了(注释的就是枚举的)
下一个进来时,我只要判断是上上次金额加这次大,还是上次大即可
answer:
class Solution {
public:
int rob(vector<int>& nums) {
int n=nums.size();
int res[n];
if(n==1)return nums[0];
if(n==2)return max(nums[0],nums[1]);
//if(n==3)return max(nums[0]+nums[2],nums[0]);
//if(n==4)return max(nums[0]+nums[2],nums[1]+nums[3]);
res[0]=nums[0];
res[1]=max(nums[0],nums[1]);
int i=2;
while(i<n){
if(res[i-2]+nums[i]>res[i-1]){
res[i]=res[i-2]+nums[i];
}else{
res[i]=res[i-1];
}
i++;
}
return res[n-1];
}
};
有一说一,DP就是数学归纳思想...
下一道多维DP
ID:62

感觉和走楼梯差不多性质,只不过是二维楼梯,而且不限步长
gg,题目看错了,是限步长的...(那就简单多了...)
难怪结果大一圈..
class Solution {
public:
int uniquePaths(int m, int n) {
if(m==1&&n==1)return 1;
if(m==1)return 1;
if(n==1)return 1;
int map[m][n];
map[0][0]=0;
map[0][1]=1;
map[1][0]=1;
int i=0;int j=0;
while(i<m){
map[i][0]=1;
i++;
}
while(j<n){
map[0][j]=1;
j++;
}
i=1;j=1;
while(i<m){
j=1;
while(j<n){
map[i][j]=map[i-1][j]+map[i][j-1];
j++;
}
i++;
}
return map[m-1][n-1];
}
};
{kind=link}
{kind=link}
 微信
微信
 支付宝
支付宝