
CPP学习日记---(四)
CPP学习日记---(四)
文件读写
tips:在构建的时候记得注意文件的相对位置,如果直接使用Makefile还好,如果是借助CMakeLists.txt,记得将对应的文件拷贝进CMake环境中
文件的打开模式
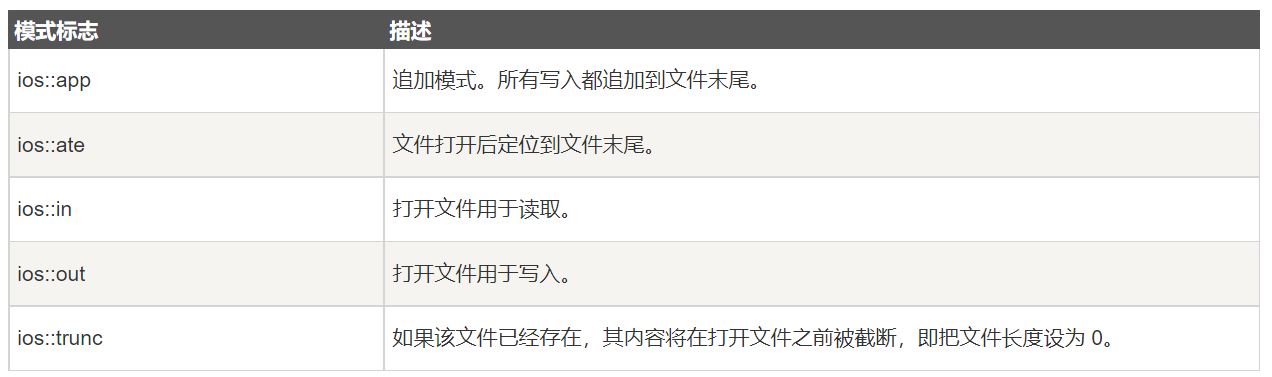
一般来说,app和trunc分开用
trunc会在写入时候用,如果文件不存在就创建,存在就清空重写
只读的时候文件一般存在,所以不会用到这些模式
流输出的时候一般都以空格符、换行符、制表符等为分隔符
基本步骤
- 流定义
- 流打开
- 异常检测(是否能打开)
- 文件读写操作
- 流关闭
异常处理
需要引入头文件库或
异常类继承树
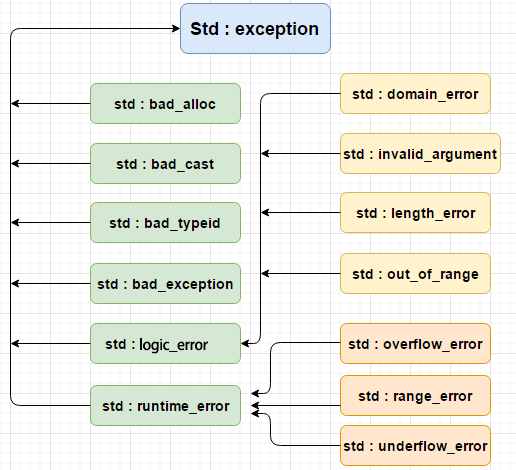
-
bad_alloc: 通过new抛出
try{ int* a=new int[100000000000000000];//bad_alloc异常处理 }catch(const exception& e){ cout<<"HEY! here is an error: "<<e.what()<<endl; } -
bad_cast:通过dynamic_cast抛出
/*转型失败异常处理测试*/ try{ second_class* base_one = new second_class(10);//已经指向了基类 //base_one = new first_child(20);//如果没有这句类型转换,会抛出相应异常 first_child* child_one = new first_child(20); first_child& child_two = dynamic_cast<first_child&>(*base_one); }catch(const exception& e){ cerr<<"HERE is an error!: "<<e.what()<<endl; } -
bad_typeid:通过typeid抛出
/*取空指针类型异常处理*/ second_class* base_one = nullptr; try{ cout<< typeid(*base_one).name()<<endl; }catch(const exception& e){ cerr<< e.what()<<endl; } -
logic_error:理论上可以通过读取代码来检测到的异常
-
runtime_error:理论上不可以通过读取代码来检测到的异常
补充知识:
- dynamic_cast 主要使用在类的继承层次结构中向下或侧向安全转型,如果在指针上使用时转换不合法会出现空指针(nullptr);如果在引用上使用时转换不合法,会出现std::bad_cast异常
异常处理的作用
- 错误隔离:通过将错误处理代码与正常的业务逻辑代码分开,可以使程序更加清晰,职责分离,便于维护和阅读。
- 错误传播:在函数调用栈中,异常可以被抛出并传递到调用栈的更高层次,直到被捕获和处理,无需显式地检查每个函数返回的错误状态。
- 资源管理:利用 C++ 的作用域规则(RAII - Resource Acquisition Is Initialization),当异常被抛出时,作用域中的所有局部对象都会被正确地销毁,这可以防止资源泄漏(如内存泄漏)。
- 明确的错误展示:异常表示函数无法正常完成其预期的操作。在某些情况下,错误可以不那么严重而可以忽略,或者通过备用逻辑修复;而在其他情况下,它们可能是致命的,需要立即处理。异常提供了一个区分这些情况的机制。
- 跨层次的错误处理:可以捕获和处理在程序的任何层次发生的错误,而不只是在错误发生的那个函数或模块里。
像刚才提到的dynamic_cast 如果转型时使用的是指针,那么转型失败不会抛出异常,而是转成空指针,这样再进行调用的话,就会出现段错误
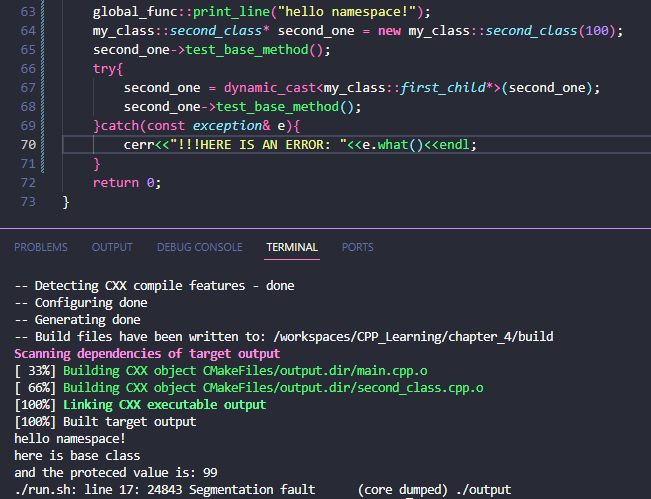
如果想使用指针进行转型,必须提前指向一个新的派生类
向上转型不用,主要是为了安全向下/侧向转型,此时还可以使用typeid来检查一下转型是否成功
另外提醒一点:如果一开始是用指针初始化,使用typeid时记得解引用,因为一开始的指针类型是固定的,但是指向的实例类型可以改变
typeid返回的
PN8my_class11first_childE(GCC、Clang)解释一下:
P 表示指针
N 表示嵌套(命名空间或者类中)
8 表示my_class长度
11 表示first_child长度
E 表示结束
命名空间
在多人协作,或者使用多个库的情况下,可能会出现命名冲突问题
为了解决该问题,我们可以使用命名空间
注意,在我们的类实现文件中常常使用的myclass::myclass(int){/**/}中,前缀并不是命名空间,而是一个作用域的分辨符,用于指明类成员的所属关系
使用using namespace可以告诉编译器,后续的代码使用该命名空间内的名称
使用规范:
一般来说会在hpp头文件中声明命名空间和内部函数(或者类),然后在cpp中进行实现
实现或使用过程中尽量避免全局使用using namespace,避免出现命名冲突
实现过程中可以使用 namespace my_class{/**/}来完成代码实现
...
tips:虽然将类放在命名空间中声明会导致使用的过程中代码变得很长,但是主题逻辑更加清晰了,还是很有必要的,尤其是在大型项目开发中
模板
模板函数
一般例子如下:
template <typename T>
const T& MIN(const T& a,const T& b){
return a<b?a:b;
}
模板类
一般例子如下
//声明
template <class T> //必备
class template_test
{
private:
std::vector<T> elems;
/* data */
public:
void push(const T&);
};
//实现
template <class T> //必备
void template_test<T>::push(const T& elem){//template_test<T>类作用域
elems.push_back(elem);
}
一般正常的函数或者类,我们都会选择在头文件中声明,然后在对应cpp文件中实现
但是模板函数或者类,我们应该在hpp头文件中就补上对应的实现代码
原理:引入头文件时,模板的定义会对编译器可见,编译器就可以为模板函数的每个实例化生成正确的代码
tips: 使用out_of_range等异常时
记得添加头文件,同时添加std::命名空间
与的区别
<exception>提供了异常处理的基础设施和基类,而<stdexcept>在此基础上提供了一系列具体的异常类,用于表示更具体的错误情况。在实际的异常处理中,通常会根据需要包含这两个头文件中的一个或两个,以便能够使用适当的异常类来反映程序中出现的特定问题。
预处理器
预处理器一般用来将宏定义、#include 等预处理指令进行替换
我们很容易联想到之前提到的内联函数,好像也是进行一个替换
但其实是有区别的:
-
宏定义的替换发生在主体编译前(预处理器处理阶段)
内联函数是编译时编译器执行的
-
宏定义是类型不安全的,因为宏定义只是进行文本替换,并不涉及前后类型的保证
内联函数是类型安全的,因为遵循正常的函数调用规则
条件编译可以用来防止重复声明、可以根据操作系统的类型来包含不同头文件
#ifdef _WIN32
#include <windows.h>
#else
#include <unistd.h>
#endif
预定义宏
测试例子如下:
cout << "Value of __LINE__ : " << __LINE__ << endl;
cout << "Value of __FILE__ : " << __FILE__ << endl;
cout << "Value of __DATE__ : " << __DATE__ << endl;
cout << "Value of __TIME__ : " << __TIME__ << endl;
多线程
创建和销毁
多线程的实现,菜鸟教程中是通过pthread库实现的:pthread库更接近底层,适用于类Unix和MacOs系统
而C++11提供的thread库,提供了面向对象的线程管理接口,跨平台性更好
以下菜鸟实现的样例我都用C++的thread库和C的pthread库实现一遍
首先,简单介绍一下pthread的线程创建过程
pthread_create(thread,attr,start_routine,arg)
其中thread是指向线程标识符的指针;attr可以用来设置线程属性
start_routine 是线程的函数起始地址,线程创建就开始执行
arg是线程运行的函数参数
值得注意的是,这里的 start_routine 和 arg 都必须是 void* 类型指针
创建成功返回0,否则返回其他
pthread_exit(void* arg)用来终止线程调用,这里的arg主要是用来进程通信的
如果使用的是pthread库,那么在编译时记得加上编译和链接选项 -pthread
C++11的thread库
thread库在pthread基础上扩展开来,可以使用函数指针、函数对象(类)、Lambda表达式作为第一个参数进行调用,第二个参数用来接收传入参数
加入和分离
在pthread中通过pthread_join()实现加入,通过pthread_detach()实现分离
在thread库中,通过join()实现加入,通过detach()实现分离(都是对象的成员函数
和thread库不同的是,pthread在进行子线程分离前需要对子线程进行属性设置,例子如下
pthread_attr_t attr;
// 初始化并设置线程为可连接的(joinable)
pthread_attr_init(&attr);// 属性初始化,默认为可加入的
// 显式设置属性为可加入
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
/*
*/
pthread_attr_destroy(&attr);// 对应属性线程创建后,删除属性,释放内存
嘿嘿,祝贺博主2024.2.22 成功脱单
找到了一个很可爱的小傻瓜,哈哈
希望看到这里的朋友能爱情事业双丰收!
参考资料
&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/02/24/20240224-202013.jpg&summary=){kind=link}
&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/02/24/20240224-202013.jpg&desc=){kind=link}
 微信
微信
 支付宝
支付宝