
CPP学习日记---(五)
CPP学习日记---(五)
STL
vector
序列容器,可以存放任何类型对象
底层由动态数组实现,支持自动扩容,连续存储
自动扩容
vector自身是支持动态扩容的,当内部容量不足时,一般会将容量翻倍,然后将旧的内容拷贝进去
测试样例中,我没有初始化vector,直接进行了push_back,连续20次后,容量显示如下

可以看到和我之前说的差不多,容量呈指数增长
而且一开始没加入元素时,内部的容量为0
string
string是存储字符的动态数组,可以看作是vector的升级版
底层内存连续,同时支持自动扩容
自动扩容
和vector类似,但string对象虽然没有初始化,但本身的容量已经有15了

小字符串优化
对于较短的字符串会直接存储在string对象的内部缓冲区中,而不是动态分配内存
map、set
map和set都是基于红黑树实现的
区别在于,map存储的是pair键值对,而set只存储了值
同时两者都保证了元素的唯一性,set适合用于不会出现重复数据的对象
出现重复数据可以使用map<T,int>,其中int来记录T出现的次数
unordered_map/set
基于散列表(哈希表)生成,通过哈希函数来将元素(键值对)映射到一个位置(哈希槽)
散列冲突
不同元素可能经过哈希函数映射到同一个位置,一般我们会采用以下两种方式解决
- 链地址法:每个哈希槽配备一个链表,如果重复了,就将元素链在对应链表中
- 开放地址法:按照某种探测寻找下个哈希槽(线性探测、二次探测等)
扩容机制
当元素容量超过装载因子时,会进行动态冲散列,创建一个更大的哈希表,重新计算所有哈希值,插入到对应的哈希槽中
list
双向链表,本身不需要扩容,因为增删都是通过节点实现
由于是双向链表,所以前后都可以进行增删
由于内部的节点都是通过链表实现的,所以增删容易查改麻烦
Mutex
一般来说都用在多线程的场景下
多个线程对同一资源进行竞争或使用
...现代CPU比较先进,如果并发任务不够多,比较难暴露出线程间的冲突
但在大型项目中,这些漏洞往往是致命的
因此引入互斥锁mutex是必要的,像下面就出现了多线程抢占情况
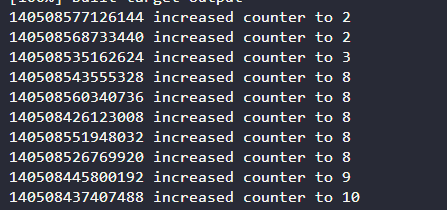
互斥锁mutex主要有以下两种使用方式
详细版(加锁、解锁)
- 全局定义std::mutex mtx
- 在共有数据单元处理操作前 mtx.lock()
- 处理共有数据
- 处理结束后 mtx.lock()
优化版
可以使用lock_guard 或者 unique_lock 实现锁管理
这是两个模板类
区别在于,lock_guard可以自动管理,更加简便
std::lock_guard<std::mutex> guard(mtx);
unique_lock可以在作用域内,重新解锁或上锁,可以做到在一些不需要互斥保护时,解锁
std::unique_lock<std::mutex> ulock(mtx);
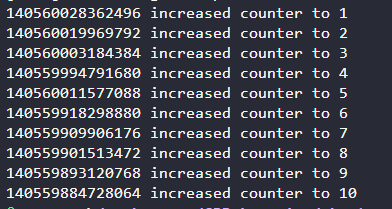
最终的互斥保护效果如下
如果不确定哪些是需要互斥保护的资源,建议还是直接使用lock_guard
不然提前解锁的话,会出现冲突现象,如下
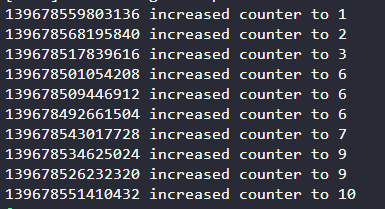
RAII
资源获取即初始化
指的是,我们申请一个资源时,会自动初始化完成
在程序生命周期,或者对象生命周期结束时回收资源
这在我们的内存分配、打开文件、锁定互斥锁时经常会用到
因为我们可能会因为程序崩溃,而导致某些资源无法正常释放,比如我加了互斥锁,但是这个线程崩了,其他线程因为这个线程占用的资源上了锁导致不能使用而阻塞
比如上面的lock_guard类就是RAII思想在mutex互斥量上的体现
智能指针
shared_ptr
我们已经知道了,shared_ptr可以实现共享所有权的时候进行引用计数
当计数为0的时候,则释放资源,实现资源的自动回收
为了更好地理解,我们也来手写一个shared_ptr模板类
主体功能
- 构造
- 拷贝构造
- 析构
- 赋值
- 解引用(操作符重载)
实现代码
详见仓库
实现效果
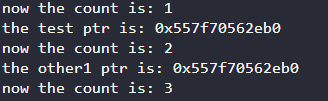
指针指向位置相同,新增共享所有权时,引用次数增加
以及测试作用域
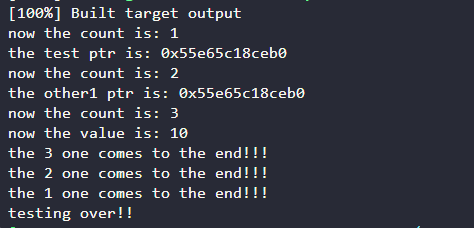
可以看到我们的所有共享指针在作用域结束时,逐个释放,最后一个释放时,释放了对象的指针和计数器
double free问题
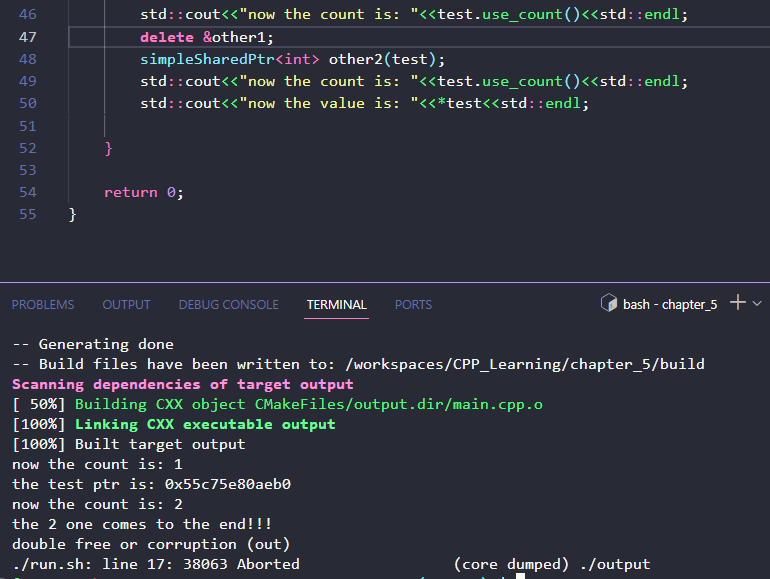
可以看到,我们在使用共享指针的时候,释放了其中一个共享者,然后再次调用会出现悬空指针
再次释放(出了作用域默认释放)时就会出现double free问题
因为原来指向的内存地址已经被释放过了,我再次释放就会导致重复释放内存
解决办法:使用weak_ptr或者使用make_shared工厂函数
我在提供的简单样例中又添加了一个reset函数
实现逻辑是,先释放共享对象的所有权,然后判断传参是否为空
如果为空就全部设成nullptr,如果有新指针,则选择新指针作为原指针,count设为新的 size_t(1)
tips: 每次作用域结束都会调用析构函数,我们在析构函数中调用内部变量(ptr或count)时要注意不要解引用空指针
线程池
学完我们的mutex和RAII思想后,我们可以自定义一个线程池类,来避免我们频繁地创建和销毁线程
主要组成
private:
- 由thread组成的动态序列,作为wokers
- 由头文件下的function可调用对象,组成的队列,作为tasks
- mutex 互斥锁(一般与下面的condition_variable同时使用)
- <condition_variable>头文件提供condition,用于通知线程工作和线程等待任务
public:
-
构造函数
-
任务入队函数(模板函数
使用库实现异步执行,使用通用引用,为后续完美转发做准备
-
析构函数
-
停止标志
构造函数
对于每个线程,workers以lambda表达式作为参数传入,其中每个lambda表达式都要无限循环等待命令
命令既可以是stop停止,也可以是任务队列中有任务
如果真的是stop停止,同时没有任务,就直接返回
否则条件满足,执行任务
任务入队函数
这是模板函数,记得定义和声明放在一起(不能分开)
通过typename std::result_of<F(Args...)>::type确定返回类型
通过bind绑定函数名和参数,这时函数已经成了一个调用对象
其中forward保证完美转发(左值右值类别)
在用packaged_task打包成随时可以调用的future(异步执行)
然后再用shared_ptr封装成共享指针,方便自动销毁
封装结束后,先用future提前留一个空位给结果
然后上锁,任务入队,解锁
提醒线程开工,异步返回结果
析构函数
上锁,然后修改停止标志
通知全体线程罢工
阻塞主线程来等待所有线程完工
测试结果

可以看到,线程池确实在重复调用之前的线程来完成任务
如果使用unique_lock 自己解锁不当的话,最后会出现互斥问题
lock_guard自动管理就好很多
通用引用
C++11引入的新引用
主要是为了判断传递给引用的值是左值还是右值
- 左值:像我们常见的变量、既可以放在=左边,也可以放在=右边
- 右值:只能作为赋值源,只能放在=右边,只是一个临时对象,不能保证之后继续存在
通用引用就可以判断传进来的是左值还是右值,以实现区别对待
std::forward
通用引用通常和std::forward同时使用
这是一个条件转发函数,传入通用引用参数时,可以直接保证传递前后类型一致
不使用forward的话会默认视为左值,失去对右值的优化操作(例如移动语义)
I/O多路复用
主要有select、poll、epoll等多路复用技术
我们的thread_pool解决了进程重复创建和销毁的问题,但是每次处理一个连接就要调用一条线程,依旧会造成不小的开销,我们就引入了I/O多路复用的概念
单线程同时监控多个文件描述符的I/O变化,当其中出现读就绪或写就绪时,等待线程处理I/O需求
select/poll
将所有的socket传入文件描述符集合,拷贝至内核,内核遍历检查是否有事件
检查结果出来后,整个集合拷贝回用户态,再遍历找到可读可写的描述符,进行处理
epoll
使用两种机制来克服了上述的复杂过程
- 红黑树存储文件描述符
- 事件发生时,仅返回带有相关文件描述符的链表
Reactor模式
这是一种特定的事件处理模式,主要用来处理并发式I/O
原理:基于事件驱动机制,中心调度器等待事件发生,然后对对应事件执行预注册的回调函数
这通常通过I/O多路复用技术实现,允许单个线程监控多个I/O事件
epoll,I/O多路复用下期好好展开,这里先这样
参考资料
&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/03/13/20240313-144030.jpg&summary=){kind=link}
&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/2024/03/13/20240313-144030.jpg&desc=){kind=link}
 微信
微信
 支付宝
支付宝