
Linux性能优化课程笔记---(一)
Linux性能优化课程笔记---(一)
概括
- 工具概览
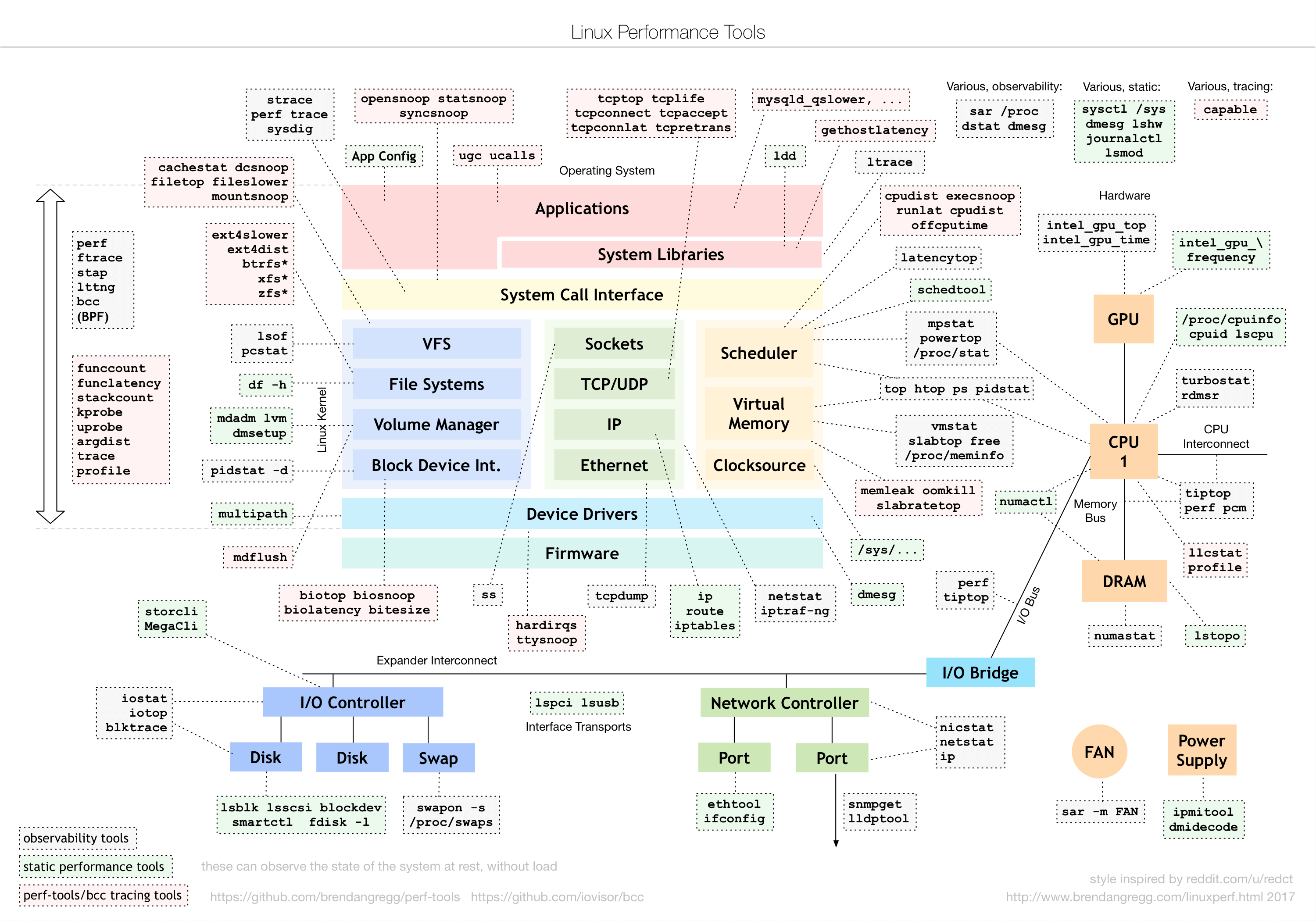
- 课程概览
CPU
前置知识
-
平均负载
什么是平均负载?
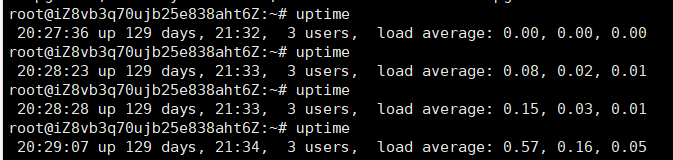
当我们在UbuntuOS环境中输入 uptime 命令时,我得到了以下输出

其中
load average字段后记录的就是平均负载(1min,5min,15min)那到底是什么呢?
:首先附上系统给出的官方回答(man手册)

平均活跃进程数(进程的指数衰减平均值),其中包含可运行和不可中断状态
-
可运行:正在使用或等待CPU的进程 ---ps中的R状态
-
不可中断:处在内核关键流程中的进程(等待I/O、磁盘)---ps中的D状态
其实这里的不可中断,很像CPP中的mutex,主要是为了保证数据操作的原子性,防止读到脏数据
当CPU数量:活跃进程数为1:1时,说明每个进程都得到了CPU(每个CPU都得到了对应的进程),利用率拉满。如果CPU多,则会空闲;进程多,则会长期等待(竞争不到CPU)
获取CPU命令如下,两行则说明有2个

多个时间的平均负载可以提供负载变化趋势
-
CPU密集型,使用大量CPU,平均负载高时,CPU利用率也高
-
I/O密集型,等待I/O使平均负载升高,但CPU使用率不一定高
-
大量进程等待CPU时也会时平均负载高,CPU使用率高
使用工具说明,apt下的
stress、sysstat包stress是Linux压测工具,sysstat包含了常用性能工具,如mpstat、pidstat
- mpstat 多核CPU性能分析工具、实时查看CPU性能指标
- pidstat 常用的进程性能分析工具,实时查看CPU、内存、I/O及上下文切换等性能指标
-
-
CPU密集型测试
测前平均负载

-
终端1

-
终端2
-
终端3
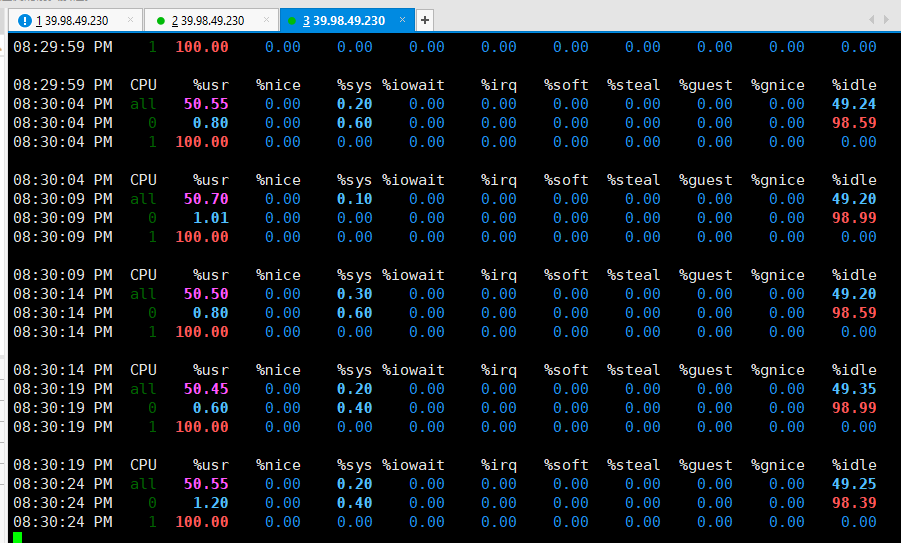
CPU使用率上升,且非I/O等待
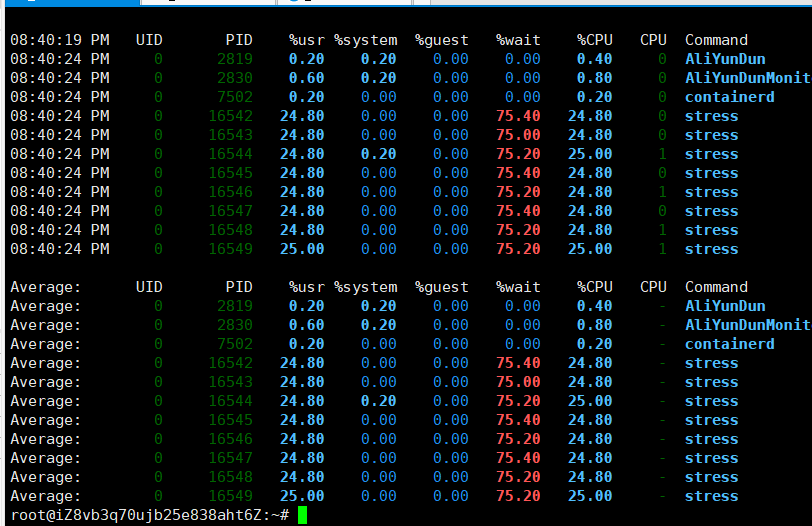
通过
pidstat发现,确实是stress命令导致CPU利用率过高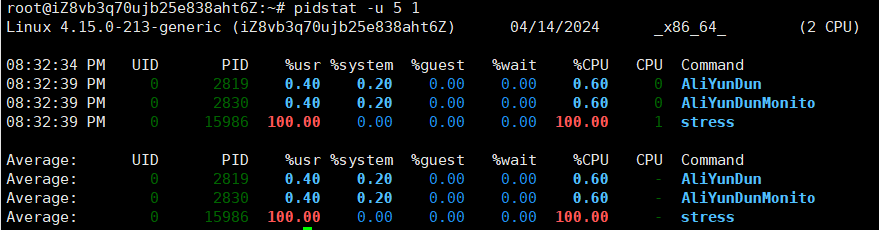
-
-
I/O密集型测试
-
终端1

-
终端2
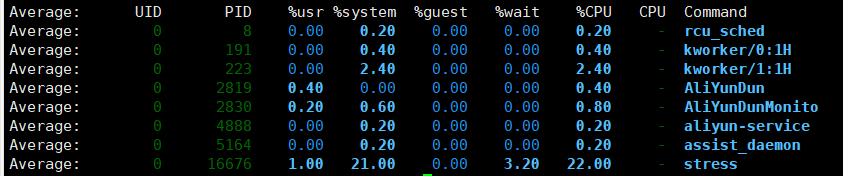
系统CPU利用率高,用户低
-
终端3
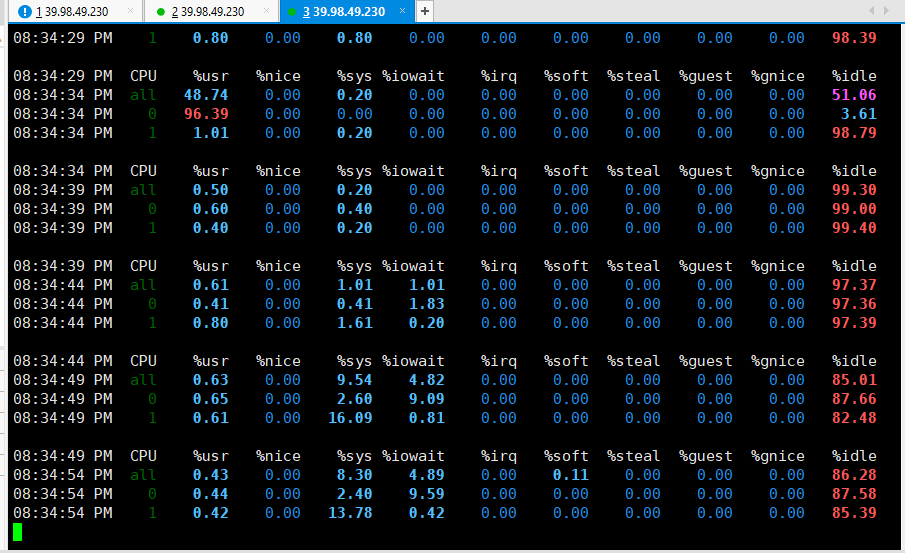
可以看到,CPU使用率下来了,iowait升高
所以平均负载依旧很高
-
-
大量进程
-
终端1

持续升高到8左右
-
终端2
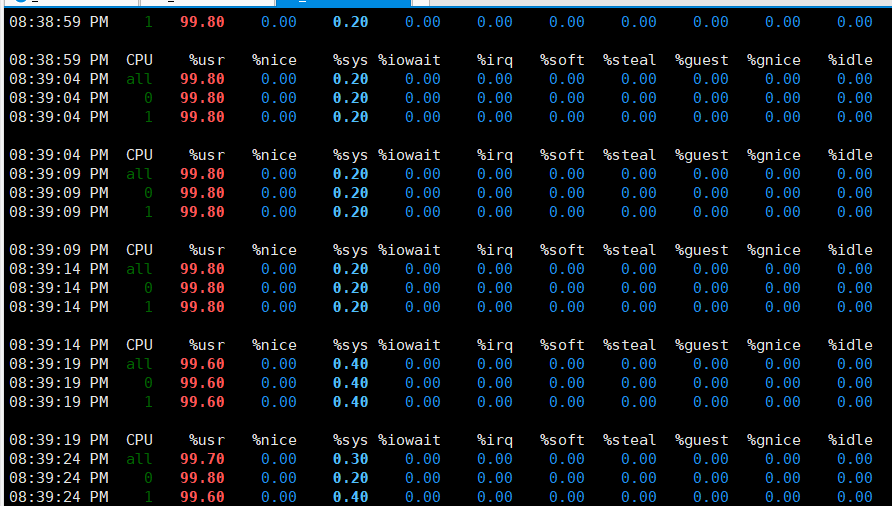
-
终端3
-
上下文切换
CPU的上下文主要包括:CPU寄存器、程序计数器(PC)
根据任务的不同,可分为进程上下文切换、线程上下文切换、中断上下文切换
-
进程上下文切换
---系统调用会发生 内核态和用户态的切换,这并不是上下文切换,而是特权模式切换,因为前后都是同一个进程,并没有出现进程的虚拟内存、栈的保存和切换
进程的大量切换会导致平均负载升高,如上节测试样例中的最后一个(大量进程)
同时,TLB的不断刷新(共享缓存,用于映射虚拟内存和物理内存)会导致映射命中率降低,从而导致内存访问变慢,其他进程等待时间加长
-
进程调度会引发进程切换,
最常用的调度方法:就绪队列(优先级最高、等待时间最长)+时间片轮转
-
-
线程上下文切换
线程是调度的基本单位,进程是资源拥有的基本单位
当线程不属于同一个进程时,线程切换即进程切换
同属于一个进程时,线程切换只需要切换栈和寄存器等,其他资源全局共享
-
中断上下文切换
中断处理会打断进程,但并不涉及到进程的用户态,不需要保存和恢复虚拟内存、全局变量等,因为中断只发生在内核态
测试一
使用工具vmstat(虚拟内存状态)
使用效果如下:
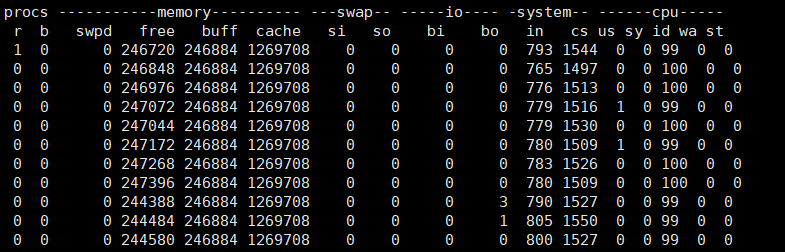
- cs(context switch):每秒上下文切换次数
- in:每秒中断次数
- r:就绪队列长度(正在运行和等待CPU的进程数)
- b:处于不可中断睡眠状态的进程数
或者使用 pidstat -w 查看具体进程上下文切换情况
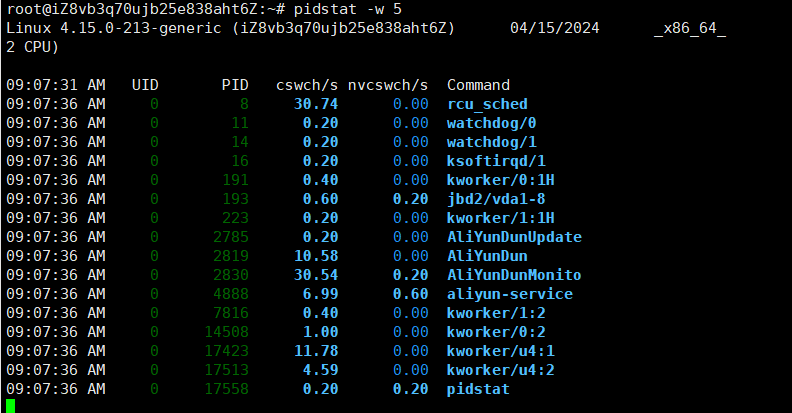
这里的cswch表示每秒自愿上下文切换次数、nvcswch表示每秒非自愿上下文切换次数
这两者意味着不同的性能问题
- 自愿上下文切换指进程无法获取所需资源,导致的上下文切换(I/O、内存资源不足)
- 非自愿上下文切换表示时间片已到等原因,被系统强制调度,从而发生上下文切换
测试二
使用工具:sysbench,多线程的基准测试模拟器(一般用来评估不同参数下数据库负载情况)
-
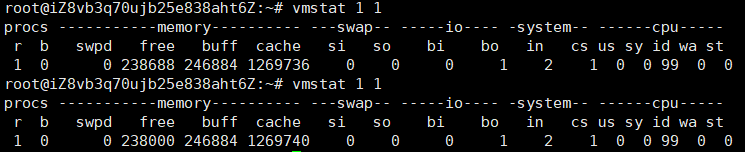
测试前环境
-
终端1
-
终端2

相当多的上下文切换和中断
其中就绪队列远超CPU核数,导致CPU竞争,引起大量上下文切换
-
终端3

除了CPU平均负载外,还有一个比较特殊的数据极速上升---中断次数,这里的中断次数为什么会上升这么快?
我们可以通过配置文件中的/proc/interrupts查看,可以发现,主要变化的是RES,即处理器中断(分散任务到不同处理器)
-
综上所述:我们的CPU切换次数其实并没有一个固定的标准,但如果出现了数量级增长或万级以上,那么很有可能出现了性能问题
出现性能问题后,首先要查看平均负载增多的原因是什么
- pidstat带来的结果中查看,是自愿上下文切换多还是非自愿多
- 自愿多则说明对应的进程出现了比较严重的I/O问题,因此需要等待I/O而放弃对CPU的占用
- 非自愿多则说明,是由于占用CPU还没处理完任务就被OS停下来了,因为时间片结束,轮到下一位进程使用了,那么CPU数量就成了性能瓶颈
- 值得一提的是,中断次数的增加也会带来一部分上下文切换开销,因此当中断次数上升时,我们应该早点查看对应的中断类型,来辅助性能瓶颈的判断
具体方式为,watch -d 查看/proc/interrupts只读文件中变化较剧烈的指标,来判断哪类中断比较频繁
- vmstat是主要的针对上下文切换的性能分析工具
sysbench在该文中主要担任模拟压测的角色,之后我会更新一版sysbench在数据库中测试的主要场景和作用
持续学习,持续进步!
以标明链接,如有侵权,请通知删除
链接
&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/mac/202502042100883.jpeg&summary=){kind=link}
&pics=https://typora-zrx.oss-cn-beijing.aliyuncs.com/img/mac/202502042100883.jpeg&desc=){kind=link}
 微信
微信
 支付宝
支付宝